Ubuntu下搭建YOLOv8训练环境
一、前言
YOLOv8作为Ultralytics推出的新一代目标检测模型,凭借高精度、高效率的核心优势,广泛应用于各类计算机视觉任务。本文将从环境前置检查、驱动适配、依赖安装,到数据集制作、模型选型、训练调参,完整拆解Ubuntu系统下YOLOv8训练环境的搭建全流程,兼顾新手友好性与实操性,帮助开发者快速搭建稳定、高效的训练环境,顺利开展目标检测任务。
二、环境前置检查与显卡驱动适配
2.1 查看显卡信息与CUDA版本兼容性
在Ubuntu终端中执行以下命令,可快速查看显卡型号、当前驱动版本及显卡支持的最高CUDA版本,为后续环境配置提供依据:
1 | nvidia-smi |
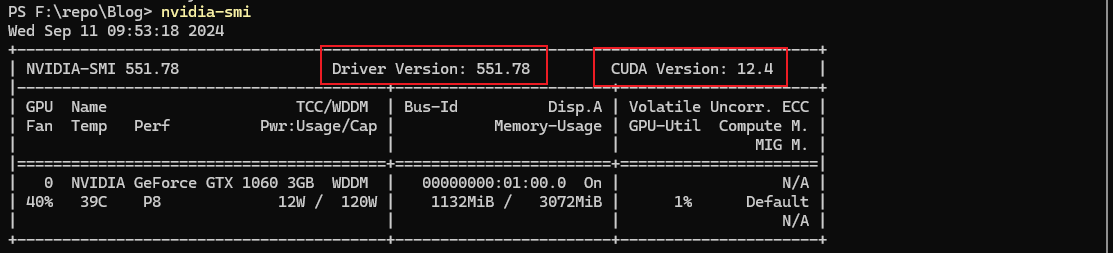
输出结果需重点关注两个核心信息:
Driver Version:显卡驱动版本,直接决定可安装的CUDA Toolkit版本,驱动版本过低会导致CUDA无法正常运行;
CUDA Version:此处显示的是显卡原生支持的最高CUDA版本(非已安装版本),后续安装的CUDA版本不得超过该数值。
版本对应规则:

参考NVIDIA官方文档(https://docs.nvidia.com/cuda/cuda-toolkit-release-notes/index.html),显卡驱动与CUDA Toolkit需严格匹配,以下为常用适配组合(供参考):
Driver Version ≥ 530.30.02 可支持 CUDA 12.1;
Driver Version ≥ 450.80.02 可支持 CUDA 11.0。
2.2 安装/更新显卡驱动(可选)
若通过上述命令查询到驱动版本过低,无法满足目标CUDA版本需求,可通过以下步骤安装NVIDIA官方驱动,确保环境兼容:
1 | # 添加NVIDIA官方驱动源 |
三、基于Conda搭建YOLOv8基础环境
3.1 安装Anaconda/Miniconda
为避免环境冲突,推荐使用Miniconda(轻量版Anaconda)管理虚拟环境,下载及安装步骤如下:
1 | # 下载Miniconda安装包(Linux x86_64架构) |
3.2 创建并激活Conda环境
创建专门用于YOLOv8训练的虚拟环境,隔离依赖包,避免与系统环境冲突:
1 | # 创建python3.12虚拟环境(建议Python版本≥3.8,适配YOLOv8最新版本) |
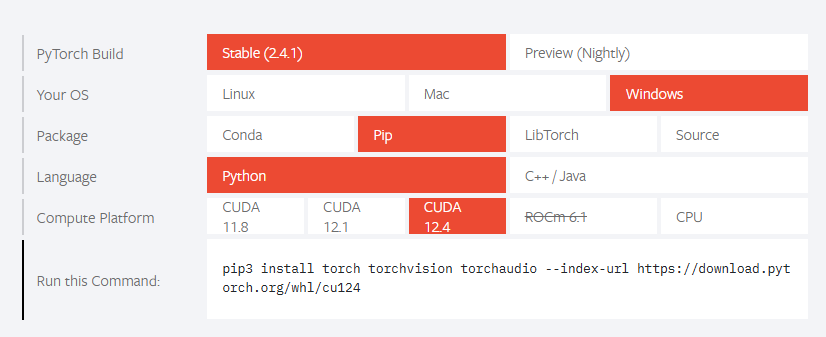
3.3 安装PyTorch(适配CUDA版本)
PyTorch是YOLOv8的核心依赖,需根据前文确认的CUDA版本选择对应安装命令。为解决官方源下载速度慢、易中断的问题,优先使用清华源加速,具体步骤如下:
3.3.1 配置清华源(临时加速,无需永久修改)
在当前终端临时配置清华源,仅对本次PyTorch及依赖包安装生效,不影响后续环境配置:
1 | # 配置清华源作为临时下载源,加速依赖包下载 |
3.3.2 安装对应CUDA版本的PyTorch
以CUDA 12.1为例(最常用版本,适配多数显卡),执行以下命令安装,已适配清华源,下载速度大幅提升:
1 | pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu121 |
若仅用于调试,无需GPU加速(不推荐用于实际训练,速度极慢),执行以下CPU版本安装命令:
1 | pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cpu |
说明:清华源主要加速PyTorch的依赖包(如numpy、pillow等)下载,PyTorch主程序仍从官方whl源获取,既保证下载速度,又能确保版本与CUDA完美适配,避免出现兼容性问题。
3.4 安装YOLOv8核心依赖
安装YOLOv8运行所需的核心依赖包,确保模型训练、预测功能正常:
1 | # 安装opencv-python(用于图像处理、视频读取等功能) |
3.5 环境验证
环境搭建完成后,执行以下命令验证是否正常可用,快速排查配置问题:
1 | yolo predict model=weights/yolov8n.pt source="https://ultralytics.com/images/bus.jpg" |
若终端输出以下信息,且在当前目录下的runs/detect/predict文件夹中生成标注后的bus.jpg图片,说明环境搭建成功,可正常开展后续训练任务:
1 | Ultralytics YOLOv8.2.58 🚀 Python-3.12.4 torch-2.3.1+cu121 CUDA:0 (NVIDIA GeForce GTX 1060 3GB, 3072MiB) |
四、自定义目标检测数据集制作
4.1 数据集目录结构(YOLO格式)
YOLOv8训练需严格遵循指定的数据集目录结构,否则会导致模型无法读取数据,推荐结构如下(清晰易维护):
1 | |-- datasets |
4.2 安装LabelImg标注工具
使用LabelImg工具进行目标标注,操作简单、支持YOLO格式,安装命令如下(沿用清华源加速,快速完成安装):
1 | # 安装LabelImg标注工具(清华源加速,避免下载超时) |
4.3 标注流程(新手友好)
打开LabelImg后,点击左上角「Open Dir」,选择待标注图片所在的文件夹(如custom_dataset/images/train);
点击左上角「Change Save Dir」,选择标签保存路径(需与图片路径对应,如custom_dataset/labels/train);
点击左侧工具栏「Create Box」(快捷键W),拖动鼠标绘制目标边界框,输入目标类别名称(如cat、dog);
标注完成后,点击「Save」(快捷键Ctrl+S),每张图片会自动生成对应的.txt标签文件,同时在标签目录下生成
classes.txt,记录所有标注类别及顺序(不可随意修改)。
4.4 划分训练集/验证集
若标注完成后未划分训练集与验证集,可通过以下Python脚本随机划分(按8:2比例,适配多数场景),脚本以VOC格式为例,直接运行即可:
1 | # voc_split_train_val.py |
执行脚本,完成训练集与验证集划分:
1 | python voc_split_train_val.py |
4.5 编写数据集配置文件(.yaml)
YOLOv8训练需通过.yaml配置文件读取数据集信息,在datasets目录下创建custom_dataset.yaml,内容如下(需根据自己的数据集修改):
1 | # 类别数量(根据自己的标注类别修改,示例为2类) |
五、YOLOv8模型选型与性能对比
YOLOv8提供5种不同尺寸的模型,分别适配不同算力场景(从入门边缘设备到高端GPU),核心性能参数对比及选型建议如下,方便开发者根据自身硬件条件和精度需求选择:
| Model | 输入尺寸(pixels) | Top1准确率 | Top5准确率 | CPU推理速度(ms) | A100 TensorRT速度(ms) | 参数量(M) | FLOPs(B)@640 |
| YOLOv8n-cls | 224 | 66.6 | 87.0 | 12.9 | 0.31 | 2.7 | 4.3 |
| YOLOv8s-cls | 224 | 72.3 | 91.1 | 23.4 | 0.35 | 6.4 | 13.5 |
| YOLOv8m-cls | 224 | 76.4 | 93.2 | 85.4 | 0.62 | 17.0 | 42.7 |
| YOLOv8l-cls | 224 | 78.0 | 94.1 | 163.0 | 0.87 | 37.5 | 99.7 |
| YOLOv8x-cls | 224 | 78.4 | 94.3 | 232.0 | 1.01 | 57.4 | 154.8 |
选型建议(贴合实际应用场景):
入门学习/边缘设备(如树莓派、低端笔记本):优先选择YOLOv8n,参数最少、速度最快,满足基础检测需求;
日常项目/平衡需求(如普通PC、中端GPU):选择YOLOv8s/YOLOv8m,兼顾检测精度与速度,适配多数场景;
高性能需求/精准检测(如服务器、高端GPU):选择YOLOv8l/YOLOv8x,精度最高,适合对检测效果要求严格的任务(需充足显存支持)。
六、YOLOv8核心训练/预测参数配置
YOLOv8训练和预测的核心参数可通过命令行直接调整,以下详细说明各参数的默认值、核心作用及调参建议,帮助开发者快速优化模型性能,避免踩坑。
6.1 训练参数(train)
| 参数 | 默认值 | 核心说明 | 调参建议 |
model |
None |
指定预训练模型路径(如yolov8m.pt),用于迁移学习 | 小数据集优先用小模型(如yolov8n.pt),减少过拟合;大数据集可选用大模型 |
data |
None |
指定数据集配置文件路径(如custom_dataset.yaml) | 必须指定,建议使用绝对路径,避免路径错误导致训练失败 |
epochs |
100 |
训练周期,即模型遍历整个数据集的次数 | 小数据集(<1k张)设20-50,大数据集设100-300;结合patience参数防止过拟合 |
batch |
16 |
每批训练的图像数量(-1为自动适配GPU显存) | 根据GPU显存调整:1060(3G)设4-8,3090(24G)设32-64;显存不足时减小批次 |
imgsz |
640 |
输入模型的图像尺寸(需为32的倍数) | 建议与数据集图片尺寸接近,最大不超过GPU显存限制;尺寸越大,精度越高但速度越慢 |
device |
None |
指定训练设备(0为第1块GPU,cpu为CPU) | 优先使用GPU训练,CPU仅用于调试;多GPU可指定0,1,2 |
lr0 |
0.01 |
初始学习率,决定模型收敛速度 | 小数据集可降低至0.001,防止过拟合;学习率过高会导致不收敛 |
weight_decay |
0.0005 |
权重衰减,用于正则化,防止模型过拟合 | 过拟合时增大至0.001,欠拟合时减小至0.0001;避免设置过大导致欠拟合 |
patience |
50 |
提前停止训练的等待周期(验证集性能无提升时) | 建议设为20-30,加速训练收敛,避免无效训练占用资源 |
label_smoothing |
0.0 |
标签平滑,减少标签标注误差带来的过拟合 | 多类别任务设0.1,单类别任务设0;标注误差大时可适当增大 |
6.2 预测参数(predict)
| 参数 | 默认值 | 核心说明 | 调参建议 |
source |
ultralytics/assets |
指定预测数据源(图片、视频、文件夹路径) | 需指定绝对路径,避免路径错误;支持网络图片、本地文件 |
conf |
0.25 |
置信度阈值,仅保留置信度高于该值的检测框 | 高精准需求(如检测关键目标)设0.5-0.7;全覆盖需求(如人群检测)设0.1-0.2 |
iou |
0.7 |
NMS交并比阈值,用于去除重叠检测框 | 重叠目标多(如人群、密集车辆)设0.3-0.5;稀疏目标设0.7-0.9 |
max_det |
300 |
单张图片的最大检测目标数量 | 按实际场景调整:检测车辆设50,检测人群设200,避免遗漏目标 |
save_txt |
False |
是否将检测结果保存为.txt标签文件(与训练标签格式一致) | 需要后续分析检测结果、二次标注时设为True |
6.3 训练命令示例(直接复制可用)
结合上述参数,提供两种常用训练命令示例,适配不同场景需求:
1 | # 基础训练命令(适合新手,参数保守,适配多数场景) |
七、总结
本文完整覆盖了Ubuntu系统下YOLOv8训练环境的搭建全流程,从环境前置检查、显卡驱动与CUDA适配,到基于Conda的虚拟环境搭建、自定义数据集制作,再到模型选型、核心参数调优,每一步均兼顾实操性与新手友好性,帮助开发者避开常见坑点,快速搭建稳定高效的训练环境。
核心要点总结:
环境适配是基础:务必确保显卡驱动、CUDA、PyTorch版本严格匹配,这是模型正常训练的前提;
数据集是关键:严格遵循YOLO格式的目录结构,标注准确、类别清晰,避免因数据集问题导致训练失败;
调参是核心:根据数据集大小、GPU显存条件,合理调整batch、epochs、lr0等参数,平衡模型精度与训练速度;
模型选型按需而定:无需盲目追求大模型,结合自身硬件条件和检测需求,选择最适配的模型尺寸。
通过本文所述步骤,开发者可快速完成YOLOv8训练环境搭建,并顺利开展自定义目标检测任务,后续可根据实际检测效果进一步优化参数,提升模型性能。