Spring家族越来越强大,作为一名javaWeb开发人员,学习Spring家族的东西是必须的。在此记录学习Spring-data-jpa的相关知识,方便后续查阅。
一、spring-data-jpa的简单介绍 SpringData : Spring 的一个子项目。用于简化数据库访问,支持NoSQL 和 关系数据存储。其主要目标是使数据库的访问变得方便快捷。
SpringData 项目所支持 NoSQL 存储:
MongoDB (文档数据库)
Neo4j(图形数据库)
Redis(键/值存储)
Hbase(列族数据库)
SpringData 项目所支持的关系数据存储技术:
JPA Spring Data : 致力于减少数据访问层 (DAO) 的开发量, 开发者唯一要做的就只是声明持久层的接口,其他都交给 Spring Data JPA 来帮你完成!
框架怎么可能代替开发者实现业务逻辑呢?比如:当有一个 UserDao.findUserById() 这样一个方法声明,大致应该能判断出这是根据给定条件的 ID 查询出满足条件的 User 对象。Spring Data JPA 做的便是规范方法的名字,根据符合规范的名字来确定方法需要实现什么样的逻辑。
Spring Data JPA 进行持久层(即Dao)开发一般分三个步骤:
声明持久层的接口,该接口继承 Repository(或Repository的子接口,其中定义了一些常用的增删改查,以及分页相关的方法)。
在接口中声明需要的业务方法。Spring Data 将根据给定的策略生成实现代码。
在 Spring 配置文件中增加一行声明,让 Spring 为声明的接口创建代理对象。配置了 jpa:repositories 后,Spring 初始化容器时将会扫描 base-package 指定的包目录及其子目录,为继承 Repository 或其子接口的接口创建代理对象,并将代理对象注册为 Spring Bean,业务层便可以通过 Spring 自动封装的特性来直接使用该对象。
二、QuickStart (1)创建项目并添加Maven依赖 首先我们在eclipse中创建一个Maven的java项目,然后添加依赖。
项目结构见右图:
主要依赖有:
spring-data-jpa
Hibernate相关依赖
c3p0依赖
mysql驱动
pom.xml文件的代码如下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>com.zxy</groupId> <artifactId>springdata-demo</artifactId> <version>0.0.1-SNAPSHOT</version> <properties> <project.source.encoding>utf-8</project.source.encoding> <project.build.sourceEncoding>UTF-8</project.build.sourceEncoding> <argLine>-Dfile.encoding=UTF-8</argLine> </properties> <dependencies> <dependency> <groupId>junit</groupId> <artifactId>junit</artifactId> <version>4.11</version> <scope>test</scope> </dependency> <dependency> <groupId>org.springframework.data</groupId> <artifactId>spring-data-jpa</artifactId> <version>1.11.7.RELEASE</version> </dependency> <dependency> <groupId>org.hibernate</groupId> <artifactId>hibernate-core</artifactId> <version>5.0.11.Final</version> </dependency> <dependency> <groupId>org.hibernate</groupId> <artifactId>hibernate-entitymanager</artifactId> <version>5.0.11.Final</version> </dependency> <dependency> <groupId>com.mchange</groupId> <artifactId>c3p0</artifactId> <version>0.9.5.2</version> </dependency> <dependency> <groupId>mysql</groupId> <artifactId>mysql-connector-java</artifactId> <version>5.1.29</version> </dependency> </dependencies> <build> <plugins> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-compiler-plugin</artifactId> <version>2.5.1</version> <configuration> <source>1.8</source> <target>1.8</target> <encoding>utf-8</encoding> </configuration> </plugin> </plugins> </build> </project>
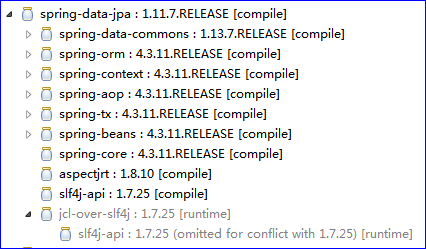
这里我解释下为何不添加Spring的其他的依赖,主要是spring-data-jpa这个依赖了一堆spring相关的依赖。见下图就明白了
(2)整合SpringData,配置applicationContext.xml 这个整合很重要,我在网上找了好久,没找到特别好的demo;因此特意把这一步记录下来。
<1> 首先我们添加一个和数据库相关的properties文件;新建db.properties文件,内容如下
1 2 3 4 5 6 jdbcUrl=jdbc:mysql://localhost:3306/springdata?useUnicode=true&characterEncoding=utf8 driverClass=com.mysql.jdbc.Driver user=root password=root initialPoolSize=10 maxPoolSize=30
<2> 然后我们需要新建一个Spring的配置文件,因此新建一个applicationContext.xml文件。里面大致配置的东西有:
开启包扫描,扫描service层,让service层的对象交给Spring容器管理
读取properties文件
配置数据源dataSource
配置JPA的EntityManagerFactory, 这里面有个包扫描,是扫描实体类那一层的
配置事务管理器transactionManager
配置支持注解的事务
配置SpringData这里包扫描是扫描dao层,扫描那些定义的接口
文件里面的具体内容如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 <?xml version="1.0" encoding="UTF-8"?> <beans xmlns="http://www.springframework.org/schema/beans" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:context="http://www.springframework.org/schema/context" xmlns:tx="http://www.springframework.org/schema/tx" xmlns:jpa="http://www.springframework.org/schema/data/jpa" xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans-4.0.xsd http://www.springframework.org/schema/context http://www.springframework.org/schema/context/spring-context-4.0.xsd http://www.springframework.org/schema/data/jpa http://www.springframework.org/schema/data/jpa/spring-jpa-1.3.xsd http://www.springframework.org/schema/tx http://www.springframework.org/schema/tx/spring-tx-4.0.xsd"> <context:component-scan base-package="com.zxy.service"/> <context:property-placeholder location="classpath:db.properties"/> <bean id="dataSource" class="com.mchange.v2.c3p0.ComboPooledDataSource"> <property name="jdbcUrl" value="${jdbcUrl}"/> <property name="driverClass" value="${driverClass}"/> <property name="user" value="${user}"/> <property name="password" value="${password}"/> <property name="initialPoolSize" value="${initialPoolSize}"/> <property name="maxPoolSize" value="${maxPoolSize}"/> </bean> <bean id="entityManagerFactory" class="org.springframework.orm.jpa.LocalContainerEntityManagerFactoryBean"> <property name="dataSource" ref="dataSource"/> <property name="jpaVendorAdapter"> <bean class="org.springframework.orm.jpa.vendor.HibernateJpaVendorAdapter"></bean> </property> <property name="packagesToScan" value="com.zxy.entity"/> <property name="jpaProperties"> <props> <prop key="hibernate.ejb.naming_strategy">org.hibernate.cfg.ImprovedNamingStrategy</prop> <prop key="hibernate.dialect">org.hibernate.dialect.MySQL5InnoDBDialect</prop> <prop key="hibernate.show_sql">true</prop> <prop key="hibernate.format_sql">true</prop> <prop key="hibernate.hbm2ddl.auto">update</prop> </props> </property> </bean> <bean id="transactionManager" class="org.springframework.orm.jpa.JpaTransactionManager"> <property name="entityManagerFactory" ref="entityManagerFactory"/> </bean> <tx:annotation-driven transaction-manager="transactionManager"/> <jpa:repositories base-package="com.zxy.dao" entity-manager-factory-ref="entityManagerFactory"> </jpa:repositories> </beans>
(3)测试整合 <1> 先测试下Spring容器是否整合成功
我们在com.zxy.test包中新建一个TestConfig的类,在类里面我们写单元测试的代码。主要内容有:
通过静态代码块创建 ClassPathXmlApplicationContext对象,让它读取applicationContext.xml,这样就启动了Spring容器
通过Spring容器获取dataSource对象,如果成功获取,说明整合成功了。
代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 package com.zxy.test; import org.springframework.context.ApplicationContext; import org.springframework.context.support.ClassPathXmlApplicationContext; import java.sql.SQLException; import javax.sql.DataSource; import org.junit.Test; public class TestConfig { private static ApplicationContext ctx ; static { ctx = new ClassPathXmlApplicationContext("classpath:applicationContext.xml"); } @Test public void testDataSouce() throws SQLException { DataSource dataSouce = (DataSource) ctx.getBean("dataSource"); System.out.println("数据源:"+ dataSouce); System.out.println("连接:"+ dataSouce.getConnection()); } }
成功后控制台输出结果如下:
<2> 测试JPA是否整合成功
JPA是否整合成功主要是看entityManagerFactory这个对象是否起作用,这个对象起作用了就会去扫描com.zxy.eneity下面的实体类。测试方法如下:
有一个前提,数据库必须先创建。这里springdata这个数据库我先创建了
给实体类加上注解,然后开启Hibernate自动建表功能,启动Spring容器;如果数据库自动建表成功,那就整合成功
实体类的代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 package com.zxy.entity; import java.util.Date; import javax.persistence.Column; import javax.persistence.Entity; import javax.persistence.GeneratedValue; import javax.persistence.GenerationType; import javax.persistence.Id; import javax.persistence.Table; @Entity @Table(name="jpa_persons") public class Person { @Id @GeneratedValue(strategy=GenerationType.IDENTITY) private Integer id; @Column private String name; @Column private String email; @Column private Date birth; public Integer getId() { return id; } public void setId(Integer id) { this.id = id; } public String getName() { return name; } public void setName(String name) { this.name = name; } public String getEmail() { return email; } public void setEmail(String email) { this.email = email; } public Date getBirth() { return birth; } public void setBirth(Date birth) { this.birth = birth; } }
添加完这个实体后,还是运行下TestConfig下的testDataSource方法,运行完后,数据库应该已经创建了一张表了。
如果表创建成功,那就代表JPA整合成功。
(4)在dao层声明接口 在框架整合完成后,我们就可以开始使用SpringData了,在(3)中我们新建了一个Person实体类,我们就利用这个Person类来展开讲解。
使用SpringData后,我们只需要在com.zxy.dao层声明接口,接口中定义我们要的方法,且接口继承Repository接口或者是Repository的子接口,这样就可以操作数据库了。但是在接口中定义的方法是要符合一定的规则的,这个规则在后面会讲到。其实我们也可以写接口的实现类,这个在后续也会讲解。
先新建一个名为PersonDao的接口,它继承Repository接口;继承Repository接口的时候那两个泛型需要指定具体的java类型。第一个泛型是写实体类的类型,这里是Person;第二个泛型是主键的类型,这里是Integer。 在这个接口中定义一个叫做getById(Integer id)的方法,然后我们后面在调用这个方法测试下。
PersonDao的代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 package com.zxy.dao; import org.springframework.data.repository.Repository; import org.springframework.data.repository.RepositoryDefinition; import com.zxy.entity.Person; public interface PersonDao extends Repository<Person, Integer> { Person getById(Integer id); }
其实也可以用注解@RepositoryDefination来代替继承接口Repository接口,这里不做过多介绍这个注解,更多和该注解的相关知识请查阅相关资料。
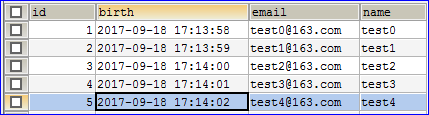
(5)测试dao层接口 由于我们数据库中jpa_persons这个表还没数据,先在这表中手动插入几条测试数据。
有了数据后,我们在com.zxy.test层新建一个名为TestQucikStart的测试类。还是采用静态代码快的方式来加载Spring配置文件的方式来使用Spring容器,在后续贴的代码中,这部分代码可能会不贴出来。这里先声明一下,后续在代码中看到的_ctx_是其实就是Spring容器的意思,它都是这样获取的。
测试类代码如下:
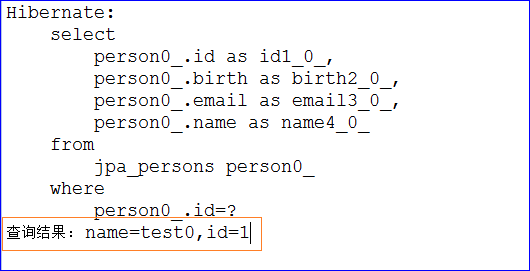
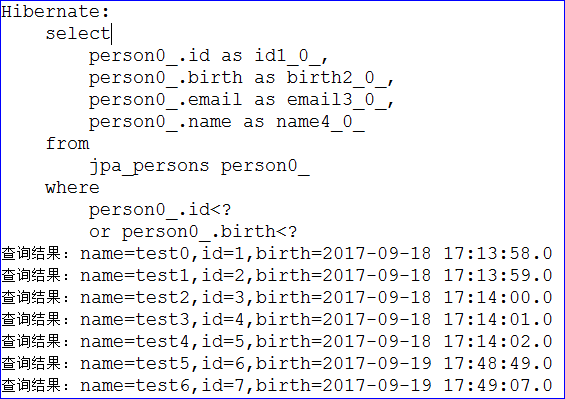
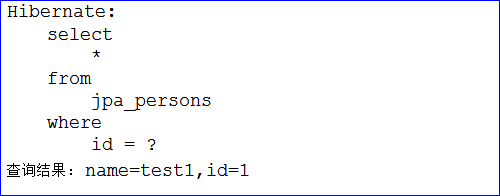
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 package com.zxy.test; import org.junit.Test; import org.springframework.context.ApplicationContext; import org.springframework.context.support.ClassPathXmlApplicationContext; import com.zxy.dao.PersonDao; import com.zxy.entity.Person; public class TestQuickStart { private static ApplicationContext ctx ; static { ctx = new ClassPathXmlApplicationContext("classpath:applicationContext.xml"); } @Test public void testGetById() { PersonDao personDao = ctx.getBean(PersonDao.class); Person person = personDao.getById(1); System.out.println("查询结果: name=" + person.getName() + ",id=" + person.getId()); } }
测试的结果如下图所示,我们只声明了接口和定义了方法就从数据库查到了数据,这就是SpringData的强大之处。
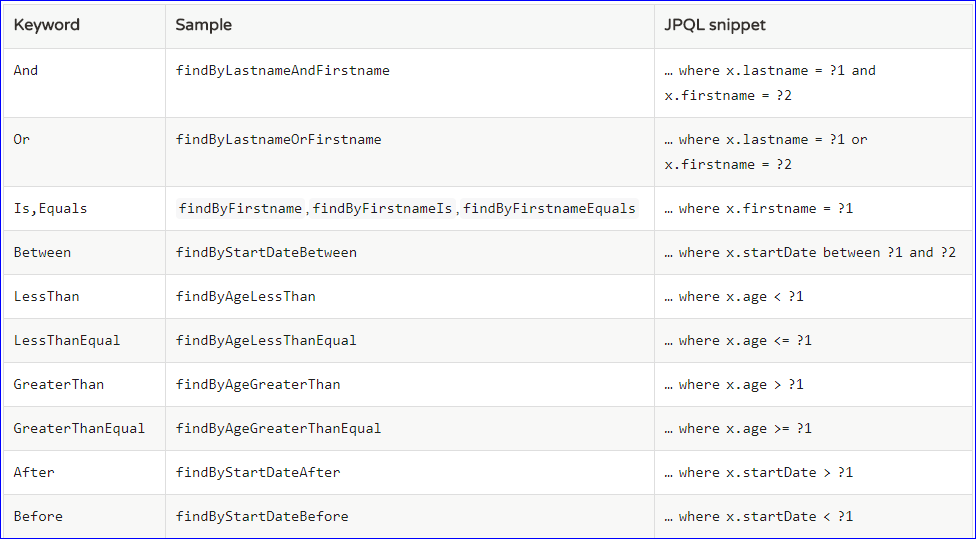
三、SpringData方法定义规范 通过上面的QucikStart的案例,我们了解到在使用SpringData时只需要定义Dao层接口及定义方法就可以操作数据库。但是,这个Dao层接口中的方法也是有定义规范的,只有按这个规范来,SpringData才能识别并实现该方法。下面来说说方法定义的规范。
(1)简单的条件查询的方法定义规范 方法定义规范如下:
简单条件查询:查询某一个实体或者集合
按照SpringData规范,查询方法于find|read|get开头,涉及条件查询时,条件的属性用条件关键字连接,要注意的是:属性首字母需要大写。
支持属性的级联查询;若当前类有符合条件的属性, 则优先使用, 而不使用级联属性。 若需要使用级联属性, 则属性之间使用 _ 进行连接。
下面来看个案例吧,操作的实体依旧上面的Person,下面写个通过id和name查询出Person对象的案例。
在PersonDao这个接口中,定义一个通过id和name查询的方法
1 2 // 通过id和name查询实体,sql: select * from jpa_persons where id = ? and name = ? Person findByIdAndName(Integer id, String name);
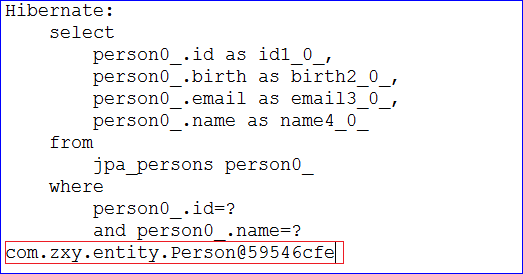
在TestQucikStart这个测试类中,写个单元测试方法testFindByIdAndName来测试这个dao层的方法是否可用
1 2 3 4 5 6 7 @Test public void testGetByIdAndName() { PersonDao personDao = ctx.getBean(PersonDao.class); Person person = personDao.findByIdAndName(1, "test0"); System.out.println(person); }
运行的结果如下,成功的查询到了数据
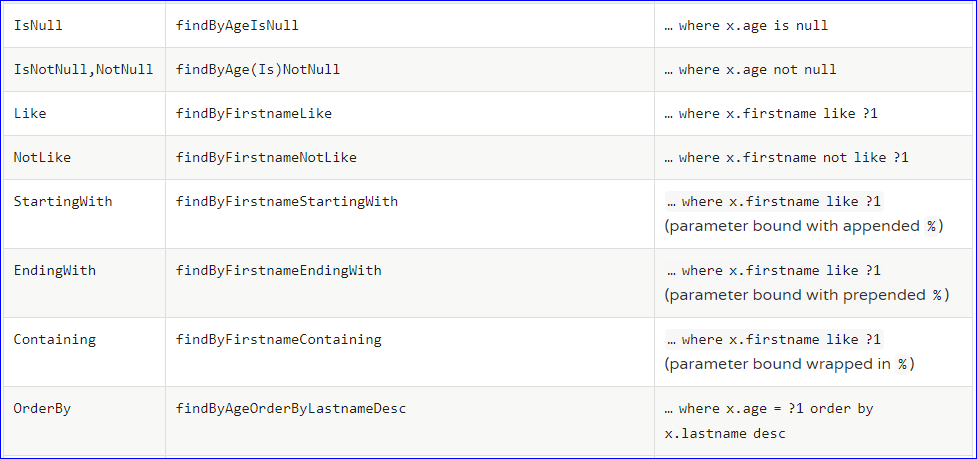
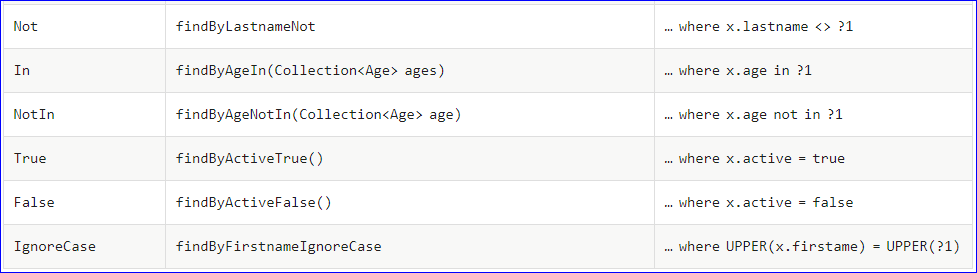
(2)支持的关键字 直接在接口中定义方法,如果符合规范,则不用写实现。目前支持的关键字写法如下:
下面直接展示个案例来介绍下这些方法吧,
PersonDao接口新增代码如下:
1 2 3 4 5 6 7 8 List<Person> findByIdIsLessThanOrBirthLessThan(Integer id, Date birth); List<Person> findByEmailLike(String email); long countByEmailLike(String email);
在TestQucikStart中添加以下2个单元测试方法,测试dao层接口中的方法是否可用
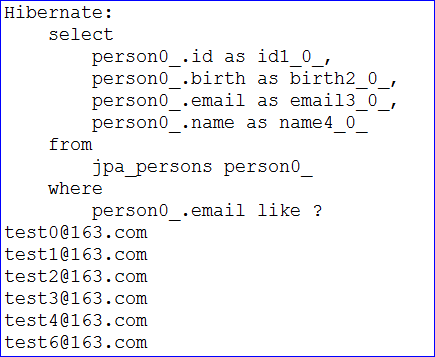
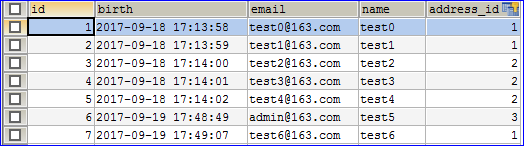
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 @Test public void testFindByEmailLike() { PersonDao personDao = ctx.getBean(PersonDao.class); List<Person> list = personDao.findByEmailLike("test%"); for (Person person : list) { System.out.println(person.getEmail()); } } @Test public void testFindByIdIsLessThanOrBirthLessThan() { PersonDao personDao = ctx.getBean(PersonDao.class); List<Person> list = personDao.findByIdIsLessThanOrBirthLessThan(3, new Date()); for (Person person : list) { System.out.println("查询结果: name=" + person.getName() + ",id=" + person.getId() + ",birth=" + person.getBirth()); } }
运行结果如下:
(3)一个属性级联查询的案例 Dao层接口中定义的方法支持级联查询,下面通过一个案例来介绍这个级联查询:
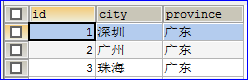
运行我们上面的任意一个测试方法,只要启动了项目,数据库的表都会更新。在表更新后我们需要手动插入一些数据,我插入的数据如下:
修改jpa_persons表,使address_id这个外键列有值,修改后的效果如下图:
在PersonDao接口中定义一个方法,代码如下:
1 2 List<Person> findByAddressId(Integer addressId);
在TestQucik这个测试类中定义一个单元测试方法,测试这个dao的方法是否可用。代码如下:
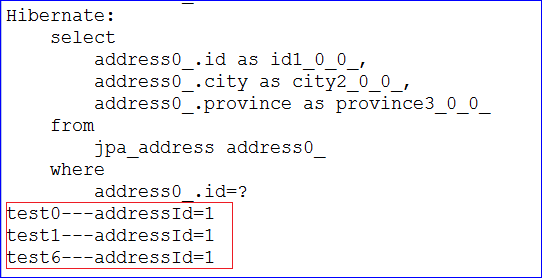
1 2 3 4 5 6 7 8 9 10 11 12 @Test public void testFindByAddressId() { PersonDao personDao = ctx.getBean(PersonDao.class); List<Person> list = personDao.findByAddressId(1); for (Person person : list) { System.out.println(person.getName() + "---addressId=" + person.getAddress().getId()); } }
运行测试方法,通过控制台可观察生成的sql语句和查询的结果。结果如下图所示:
这里我解释下这个生成的sql吧,首先是一个左外连接查询出结果,由于Person中有个Address的实体,所以就又发送了一次查询address的sql。产生这个的原因是@ManyToOne这个注解默认是禁用延迟加载的,所以会把关联属性的值也会查询出来。
(4)查询方法解析流程 通过以上的学习,掌握了在接口中定义方法的规则,我们就可以定义出很多不用写实现的方法了。这里再介绍下查询方法的解析的流程吧,掌握了这个流程,对于定义方法有更深的理解。
<1> 方法参数不带特殊参数的查询
假如创建如下的查询:findByUserDepUuid(),框架在解析该方法时,流程如下:
首先剔除 findBy,然后对剩下的属性进行解析,假设查询实体为Doc
先判断 userDepUuid(根据 POJO 规范,首字母变为小写)是否为查询实体的一个属性,如果是,则表示根据该属性进行查询;如果没有该属性,继续往下走
从右往左截取第一个大写字母开头的字符串(此处为Uuid),然后检查剩下的字符串 是否为查询实体的一个属性,如果是,则表示根据该属性进行查询;如果没有该属性,则重复这一步,继续从右往左截取;最后假设 user 为查询实体的一个属性
接着处理剩下部分(DepUuid),先判断 user 所对应的类型是否有depUuid属性,如果有,则表示该方法最终是根据 “Doc.user.depUuid” 的取值进行查询;否则继续按照步骤3的规则从右往左截取,最终表示根据 “Doc.user.dep.uuid” 的值进行查询。
可能会存在一种特殊情况,比如 Doc包含一个 user 的属性,也有一个 userDep 属性,此时会存在混淆。可以明确在级联的属性之间加上 “_“ 以显式表达意图,比如 “findByUser_DepUuid()” 或者 “findByUserDep_uuid()”。
<2> 方法参数带特殊参数的查询
特殊的参数: 还可以直接在方法的参数上加入分页或排序的参数,比如:
Page findByName(String name, Pageable pageable)
List findByName(String name, Sort sort);
四、@Query注解 通过上面的学习,我们在dao层接口按照规则来定义方法就可以不用写方法的实现也能操作数据库。但是如果一个条件查询有多个条件时,写出来的方法名字就太长了,所以我们就想着不按规则来定义方法名。我们可以使用@Query这个注解来实现这个功能,在定义的方法上加上@Query这个注解,将查询语句声明在注解中,也可以查询到数据库的数据。
(1)使用Query结合jpql语句实现自定义查询
在PersonDao接口中声明方法,放上面加上Query注解,注解里面写jpql语句,代码如下:
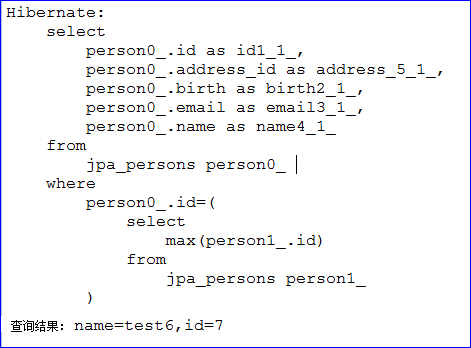
1 2 3 4 5 6 7 @Query("from Person where id < ?1 or name like ?2") List<Person> testPerson(Integer id, String name); @Query("from Person where id = (select max(p.id) from Person as p)") Person testSubquery();
在TestQuickStart中添加以下代码,测试dao层中使用Query注解的方法是否可用
1 2 3 4 5 6 7 8 9 10 11 12 @Test public void testCustomMethod() { PersonDao personDao = ctx.getBean(PersonDao.class); List<Person> list = personDao.testPerson(2, "%admin%"); for (Person person : list) { System.out.println("查询结果: name=" + person.getName() + ",id=" + person.getId()); } System.out.println("===============分割线==============="); Person person = personDao.testSubquery(); System.out.println("查询结果: name=" + person.getName() + ",id=" + person.getId()); }
(2)索引参数和命名参数 在写jpql语句时,查询条件的参数的表示有以下2种方式:
说一个特殊情况 ,那就是自定义的Query查询中jpql语句有like查询时,可以直接把%号写在参数的前后,这样传参数就不用把%号拼接进去了。使用案例如下,调用该方法时传递的参数直接传就ok。

(3)使用@Query来指定使用本地SQL查询 如果你不熟悉jpql语句,你也可以写sql语句查询,只需要在@Query注解中设置nativeQuery=true。直接来看案例吧

测试代码这里直接不贴了,下面是控制台中打印的语句和结果
五、@Modifying注解和事务 (1)@Modifying注解的使用 @Query与@Modifying这两个注解一起使用时,可实现个性化更新操作及删除操作;例如只涉及某些字段更新时最为常见。
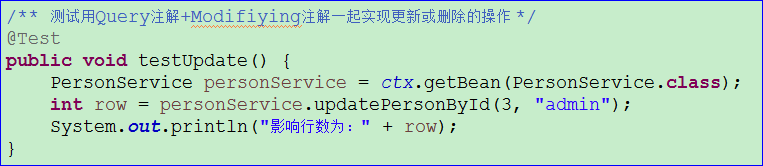
下面演示一个案例,把id小于3的person的name都改为’admin’
1 2 3 4 5 6 7 @Modifying @Query("UPDATE Person p SET p.name = :name WHERE p.id < :id") int updatePersonById(@Param("id")Integer id, @Param("name")String updateName);
由于这个更新操作,只读事务是不能实现的,因此新建PersonService类,在Service方法中添加事务注解。PersonService的代码如下图所示
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 package com.zxy.service; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.stereotype.Service; import org.springframework.transaction.annotation.Transactional; import com.zxy.dao.PersonDao; @Service("personService") public class PersonService { @Autowired private PersonDao personDao; @Transactional(readOnly=false) public int updatePersonById(Integer id, String updateName) { return personDao.updatePersonById(id, updateName); } }
使用@Modifying+@Query时的注意事项 :
方法返回值是int,表示影响的行数
在调用的地方必须加事务,没事务不执行
(2)事务
Spring Data 提供了默认的事务处理方式,即所有的查询均声明为只读事务。
对于自定义的方法,如需改变 Spring Data 提供的事务默认方式,可以在方法上注解 @Transactional 声明
进行多个 Repository 操作时,也应该使它们在同一个事务中处理,按照分层架构的思想,这部分属于业务逻辑层,因此,需要在 Service 层实现对多个 Repository 的调用,并在相应的方法上声明事务。
六、本文小结 (1)本文只简单介绍了下SpringData,知道了SpringData简化了dao层的代码,我们可以只声明接口就可以完成对数据库的操作。
(2)介绍了一个SpringData的入门案例,其中包含了需要哪些依赖的jar包,如何整合Spring-data-jpa以及怎么测试是否整合成功等。
(3)介绍了Dao层接口继承了Repository接口后,该按照什么规则去定义方法就可以被SpringData解析;且展示了SpringData对级联查询的案例。同时也讲解了SpringData解析方法的整个流程。
(4)介绍了@Query注解的使用,有了这个注解,我们就可以随便定义方法的名字,方法的功能由我们自己写jqpl语句或者是sql语句来实现。在介绍这个注解的时候,也讲解了jpql或者sql中参数可以用索引参数和命名参数的两种方式来表示。
(5)介绍了@Modifying注解结合@Query注解,实现更新和删除。同时也介绍了SpringData的事务。