Qt学习笔记-1
1. 第一个Qt程序
1.1 Hello Qt
1 |
|
测试程序
在源码根目录打开命令提示符执行qmake -project生成hello.pro项目文件,然后执行qmake hello.pro从这个项目文件生成makefile文件,在输入make命令就可以构建该应用。
Docker容器互访三种方式
方式一、虚拟ip访问
安装docker时,docker会默认创建一个内部的桥接网络docker0,每创建一个容器分配一个虚拟网卡,容器之间可以根据ip互相访问。
1 | # ifconfig |
运行一个centos镜像, 查看ip地址得到:172.17.0.7
1 | # docker run -it --name centos-1 docker.io/centos:latest |
以同样的命令再起一个容器,查看ip地址得到:172.17.0.8
1 | # docker run -it --name centos-2 docker.io/centos:latest |
容器内部ping测试结果如下:
1 | # ping 172.17.0.7 |
这种方式必须知道每个容器的ip,在实际使用中并不实用。
方式二、link
运行容器的时候加上参数link
运行第一个容器
1 | docker run -it --name centos-1 docker.io/centos:latest |
运行第二个容器
1 | docker run -it --name centos-2 \ |
--link:参数中第一个centos-1是 容器名 ,第二个centos-1是定义的 容器别名 (使用别名访问容器),为了方便使用,一般别名默认容器名。
测试结果如下:
1 | # ping centos-1 |
此方法对容器创建的顺序有要求,如果集群内部多个容器要互访,使用就不太方便。
方式三、创建bridge网络
- 安装好docker后,运行如下命令创建bridge网络:
1 | docker network create testnet |
查询到新创建的bridge testnet。
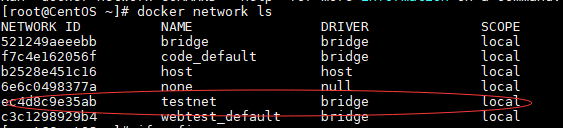
- 运行容器连接到testnet网络。
使用方法:1
2
3docker run -it --name <容器名> \
--network <bridge> \
--network-alias <网络别名> <镜像名>
1 | docker run -it --name centos-1 --network testnet \ |
- 从一个容器ping另外一个容器,测试结果如下:
1 | # ping centos-1 |
- 若访问容器中服务,可以使用这用方式访问 <网络别名>:<服务端口号>
推荐使用这种方法,自定义网络,因为使用的是网络别名,可以不用顾虑ip是否变动,只要连接到docker内部bright网络即可互访。bridge也可以建立多个,隔离在不同的网段。
Docker部署单节点ETCD
准备
镜像选择
quay.io/coreos/etcd:3.2.7
bitname/etcd
创建ETCD数据目录
1 | # data 存储容器持久化数据 |
创建ETCD配置文件
配置文件路径为 /usr/local/docker/etcd/config/etcd.config.yml
1 | name: etcd # etcd member 名称,可根据实际情况修改 |
创建并启动ETCD服务
1 | docker run -d --name etcd -p 2379:2379 -p 2380:2380 -v /usr/local/docker/etcd/data:/var/etcd -v /usr/local/docker/etcd/config:/var/lib/etcd/config quay.io/coreos/etcd: 3.5.12 |
使用docker-compose部署
创建Docker-compose
1 | version: '3' |
基于环境变量配置, 配置参考配置文件方式
1 | version: '3' |
创建并启动etcd
1 | cd {docker-compose文件所在目录} |
测试命令
1 | etcdctl --endpoints=192.168.1.2:2379 --write-out=table endpoint health |
基于OpenCV的视频流处理
获取VideoCapture实例
1 | # 读取视频流 |
获取摄像头编号可使用ls -al /dev/ |grep video,输出信息以video开头其后缀为数字即为可能的摄像头编号。
检查获取VideoCapture实例是否成功
1 | # 校验获取VideoCapture类实例 |
获取视频流信息
1 | # 获取视频帧的宽 |
获取帧画面
1 | success, frame = capture.read() |
当需要同时处理多路摄像头时一般使用grab()和retrieve()代替
1 | success_1 = capture.grab() |
设置分辨率
1 | # 设置摄像头分辨率的宽 |
保存视频文件
无论是视频文件存储还是摄像头画面保存都是用VideoWriter类,初始化时需要传入文件名(包含文件格式)、视频编解码器、视频保存帧率 、分辨率,保存视频的帧率最好和读入的帧率一致,分辨率可以更改,只是要求写入的帧大小要与分辨率保持一致。
若指定的文件名已存在则会覆盖文件。
1 | writer = cv2.VideoWriter('output.mp4', |
释放资源
不管是VideoCapture还是VideoWriter类,使用完都应该释放资源
1 | # 释放VideoCapture资源 |
完整示例
1 | # -*- coding: utf-8 -*- |
Docke种使用GPU运行Ollama
环境安装
此处使用设备 Tesla P40 + Debian 12为例
显卡驱动:下载 NVIDIA 官方驱动 | NVIDIA
CUDA Toolkit: CUDA Toolkit Archive | NVIDIA Developer
![[Docke种使用GPU运行Ollama/IMG-20260105103041635.png]]
注意CUDA版本对应,否则可能会导致CUDA在容器内无法运行
1 | curl -fsSL https://nvidia.github.io/libnvidia-container/gpgkey | sudo gpg --dearmor -o /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg \ |
禁用 nouveau
参考[[../Linux/Ubuntu禁用Nouveau驱动|Ubuntu禁用Nouveau驱动]]验证环境是否安装成功
1
docker run --rm --gpus all nvidia/cuda:12.2.0-runtime-ubuntu22.04 nvidia-smi
![[Docke种使用GPU运行Ollama/IMG-20260105103041714.png]]
直接运行Docker容器
1. 运行Ollama容器
1 | docker run --gpus=all -d -e OLLAMA_MODEL:qwen2.5-coder:7b -e OLLAMA_ENV:production -v=qwen-coder:/root/.ollama -p 11437:11434 --name qwen-coder -d ollama/ollama:latest |
- 如果不需要带显卡, 去除
--gpus=all即可 - 环境变量参考Ollama环境变量与常用CLI命令
2. 拉取模型并运行
1 | ollama run qwen2.5-coder:7b |
使用Docker Compose
1. 创建docker-compose.yml
1 | services: |
2. 启动服务
在docker-compose.yml所在目录运行以下命令:
1 | docker-compose up -d |
验证是否使用GPU启动Ollama
1 | docker exec -it <ollama容器ID> bash # 进入已启动的容器 |
如果PROCESSOR中显示为GPU则启动成功
![[Docke种使用GPU运行Ollama/IMG-20260105103041772.png]]
Ollama运行deepseek-r1示例
1 | # CPU运行 |
注意事项
- 使用_nvidia-smi_确认GPU是否被正确利用。
- 如果仅需CPU支持,可移除_–gpus=all_或相关配置。
- GPU模式下性能显著提升,但需确保驱动和CUDA版本兼容。
Ubuntu禁用Nouveau驱动
1. 创建黑名单配置文件
1 | sudo nano /etc/modprobe.d/blacklist-nouveau.conf |
- 添加以下内容以禁用Nouveau:
1 | blacklist nouveau |
2. 更新initramfs
- 更新内核的initramfs文件以应用更改:
1
sudo update-initramfs -u
3. 重启系统
- 执行以下命令重启系统:
1 | sudo reboot |
4. 验证禁用状态
重启后,检查Nouveau模块是否已禁用:
1
lsmod | grep nouveau
如果没有输出,说明Nouveau已成功禁用。
注意事项
禁用Nouveau后,可以安装NVIDIA专有驱动以获得更好的性能。
如果需要恢复Nouveau驱动,只需删除_/etc/modprobe.d/blacklist-nouveau.conf_文件并重新更新initramfs。
WPF中Binding使用StringFormat格式化字符串
货币格式
1 | <!-- 默认保留两位小数 输出: $12.34 --> |
固定文字
1 | <!-- 固定前缀 输出: 单价:$12.34 --> |
数字格式化
1 | <!-- 固定位数,仅支持整形 输出: 086723 --> |
占位符
1 | <!-- 输出: 0123.46 --> |
时间日期
1 | <!-- 输出: 5/4/2015 --> |
多重绑定
1 | <!-- |
移动端热更新技术方案解析
一、 背景与机遇:为什么需要热更新?
热更新指在不重新发布客户端安装包(APK/IPA)的情况下,通过下发补丁或脚本,在线修复Bug或更新部分功能。
核心驱动力:
- 快速迭代与修复:传统应用商店审核周期长(早期App Store可达2周),无法满足紧急Bug修复、节日活动等快速上线需求。
- 提升用户体验:避免强制用户下载完整的安装包,降低更新成本,提高版本覆盖率。
- 业务灵活性:支持A/B测试、功能灰度发布等动态化运营策略。
技术机遇(iOS侧):2013年iOS 7引入的 JavaScriptCore 框架是关键转折点。它使得原生Objective-C与JavaScript之间的高效、无缝通信成为可能,为基于JS脚本的热更新方案(如JSPatch)铺平了道路。随着Swift的发布和iOS 7+用户成为主流,热更新技术开始爆发。
二、 iOS平台热更新方案详解
1. 基于JavaScriptCore的轻量级方案(非跨平台)
这类方案适合小范围Bug修复和逻辑更新,通过JS脚本调用/替换原生方法。
| 方案 | 脚本语言 | 特点 | 现状 |
|---|---|---|---|
| Rollout.io | JavaScript | 支持OC和Swift,已平台化,有商业化产品使用。 | 成熟,持续维护。 |
| JSPatch | JavaScript | 仅支持OC,在国内广泛使用(腾讯系等),平台化成熟。 | 成熟,但苹果审核政策收紧后使用需谨慎。 |
| DynamicCocoa | OC -> JS | 滴滴内部方案。最大亮点:提供工具将OC代码转译为JS,无需手写JS;支持xib/storyboard、图片资源更新。 | 曾计划开源,需关注其后续动态。 |
共同原理:利用 JavaScriptCore 建立JS与OC的桥接,通过运行时(Runtime)动态替换方法实现(method swizzling)。
2. 跨平台应用开发方案
这类方案旨在用一套代码开发iOS、Android(及Web)应用,天然支持热更新。
| 方案 | 发起方 | 核心特点 | 性能与生态 |
|---|---|---|---|
| React Native (RN) | 使用React语法和JSX,重视各平台原生体验。 | 性能持续优化,生态庞大(Facebook、腾讯、京东等大量应用使用)。早期性能有槽点,现已大幅改善。 | |
| Weex | 阿里巴巴 | 目标:一次编写,生成iOS、Android、Web三端代码。采用Vue.js语法。 | 经阿里系产品(如2016年双11)大规模验证。旨在解决RN代码复用率、性能优化被动等问题。 |
选型提示:Weex 在代码复用和跨平台一致性上追求更极致;RN 则更强调遵循各平台原生设计规范,生态更成熟。
3. 其他方案
- Wax:使用Lua作为脚本语言,性能优于JS。代表作《愤怒的小鸟》。后期由阿里接手维护,但支付宝后期转向了JSPatch。
- Hybrid App:基于WebView(如PhoneGap)。缺点:性能较差,体验不及原生。随着RN/Weex的成熟,已不再是高性能App的首选。
关于脚本语言的思考:
- Lua:性能高,但在应用开发生态(类库、文档)上不如JS成熟,多用于游戏热更(Cocos2d-X, Unity3D)。
- JavaScript:生态极其丰富,性能足以满足大部分应用开发场景,是应用端热更的主流选择。
4. 技术背景:GCC、LLVM与Clang
- GCC:传统的编译器集合,早期OC的编译器。
- LLVM/Clang:Apple主导,旨在取代GCC。
Clang是LLVM的前端,负责将OC代码编译成抽象语法树(AST)。 - 关联:
DynamicCocoa的高明之处在于直接利用Clang生成的AST进行解析和转译,从而实现了“用OC写补丁”的体验。

三、 Android平台热修复方案详解
Android方案主要围绕DEX补丁的生成、下发和加载展开。
| 方案 | 出品方 | 核心原理 | 优点 | 缺点 |
|---|---|---|---|---|
| 百川Hotfix | 阿里巴巴 | 融合热部署(AndFix)与冷部署,支持类、资源、SO文件修复。 | 功能全面,可视化打补丁,接入简单。 | - |
| Robust | 美团 | 为每个方法插入“跳转”逻辑,通过改变跳转目标实现修复。 | 实时生效,兼容性高,稳定性好。 | 侵入打包流程,增加包体积和方法数。 |
| Tinker | 微信 | 全量替换DEX。通过自研DexDiff算法生成极小差量包。 | 补丁包小,功能强大(支持类、资源、SO)。 | 不实时生效,需重启。合并DEX时消耗内存/磁盘,可能失败。 |
| QFix (类) | 手机QQ空间 | 类似Google Multidex,将补丁作为新的DEX加载。 | 兼容性高,稳定性好。 | 不实时生效。Dalvik下性能问题;Art下补丁包大;需侵入打包。 |

关键概念:
- 实时生效:补丁应用后立即起作用,无需重启App(如Robust、AndFix)。
- 冷启动生效:补丁在下次App启动时生效(如Tinker、QFix)。
- 侵入式打包:需要在正常打包流程中插入特定步骤,可能影响CI/CD流水线。
四、 总结与方案选型快速参考
| 平台 | 需求场景 | 推荐方案 | 关键考量 |
|---|---|---|---|
| iOS | 紧急Bug修复,小功能更新 | JSPatch (需注意审核风险) 或评估 Rollout | 苹果官方对热更新审核政策严格,需谨慎使用。 |
| iOS | 新功能模块,跨平台需求 | React Native 或 Weex | RN生态更成熟;Weex追求更高代码复用。 |
| Android | 紧急Bug修复,要求实时生效 | Robust | 平衡了实时性、兼容性和稳定性。 |
| Android | 常规版本更新,修复范围大 | Tinker | 补丁包小,功能全面,社区活跃。 |
| Android | 追求简单接入,功能全面 | 百川Hotfix | 阿里系产品,提供平台化支持。 |
核心建议:
- 明确需求:是修复致命Bug,还是实现功能动态化?是否需要跨平台?
- 评估成本:接入复杂度、包体积影响、对现有构建流程的侵入程度。
- 关注生态与合规:特别是iOS方案,需密切关注苹果的审核政策动向。
- 混合使用:大型App常采用混合策略,如基础模块用原生,高动态业务模块用RN/Weex。
五、 拓展资源
- 本文参考PPT:热更新分享PPT.pptx
- iOS深入原理:
- Android方案对比:
日志搜集系统从ELK到EFK
一、为什么需要日志系统?
1.1 日志的定义与挑战
日志是程序产生的、遵循特定格式(通常包含时间戳)的文本数据。在分布式系统中,日志通常分为:
- 系统日志:操作系统和基础服务的运行状态
- 应用日志:业务应用程序的输出
- 安全日志:安全审计和访问记录
传统日志管理的痛点:
- 分散存储:日志分布在多台服务器的不同文件中
- 查找困难:故障排查时需要登录多台服务器,使用
grep/sed/awk等工具手动搜索 - 格式多样:不同应用使用不同的日志格式和滚动策略
- 实时性差:难以及时发现和响应系统问题
1.2 日志系统的价值
- 故障排查:快速定位问题根源,减少平均修复时间(MTTR)
- 系统监控:实时了解服务运行状态和性能指标
- 安全审计:追踪异常访问和潜在安全威胁
- 业务分析:基于日志数据进行用户行为分析和业务洞察
二、ELK Stack 基础架构
2.1 核心组件介绍
| 组件 | 角色 | 特点 |
|---|---|---|
| Elasticsearch | 分布式搜索引擎 | 高可扩展、高可靠、支持全文检索和结构化查询 |
| Logstash | 数据收集处理引擎 | 支持多种数据源、强大的过滤和转换能力 |
| Kibana | 数据可视化平台 | 丰富的图表类型、交互式仪表板 |
| Filebeat | 轻量级数据收集器 | 资源消耗低、专为日志收集优化 |
版本信息:
- Elasticsearch 5.2.2
- Logstash 5.2.2
- Kibana 5.2.2
- Filebeat 5.2.2
- Kafka 2.10
2.2 Logstash 数据处理流程
1 | Input → Filter → Output |
- Input插件:支持 File、Stdin、TCP、Syslog、Redis、Collectd 等
- Filter插件:
grok:正则表达式解析date:时间处理json:JSON编解码mutate:数据修改
- Output插件:支持 Elasticsearch、Redis、TCP、File 等
Grok 示例:
1 | grok { |
三、架构演进:从简单到复杂
3.1 简单版架构(学习用)
1 | 应用服务器 → Logstash → Elasticsearch → Kibana |
特点:
- Logstash 直接连接 Elasticsearch
- 部署简单,适合学习和测试
- 缺点:单点故障、资源消耗大、不适合生产环境
3.2 集群版架构
1 | 多台服务器 → Logstash Shipper → Elasticsearch集群 → Kibana |
改进:
- Elasticsearch 集群化,提高可用性
- 每台服务器部署 Logstash Agent
- 问题:
- Logstash 消耗服务器资源
- 大并发时可能丢失数据
- 不支持多机房部署
3.3 引入消息队列架构
1 | 多台服务器 → Logstash Shipper → Kafka集群 → Logstash Indexer → Elasticsearch集群 → Kibana |
关键改进:
- 引入 Kafka 作为消息队列,削峰填谷
- 分离角色:Shipper(收集)和 Indexer(处理)
- 选择 Kafka 而非 Redis 的原因:
- 数据可靠性:Kafka 保证可靠,Redis 可能丢失
- 堆积能力:Kafka 依赖磁盘,Redis 依赖内存
3.4 多机房部署架构
1 | 机房A:应用 → Logstash → Kafka → Logstash → Elasticsearch → Kibana |
单元化设计原则:
- 每个机房独立完整的日志处理链路
- 避免跨机房数据传输
- 降低网络延迟和专线成本
四、关键优化:引入 Filebeat
4.1 为什么需要 Filebeat?
Logstash 的问题:
- 基于 JVM,资源消耗高(CPU、内存)
- 安装包大(约100MB)
- 作为 Agent 运行时代价高
Filebeat 的优势:
- 用 Golang 编写,无需 JVM
- 安装包小(<10MB)
- 资源消耗极低
- 专为日志收集优化
4.2 Filebeat 配置示例
1 | filebeat.prospectors: |
4.3 性能对比测试
测试环境:
- 虚拟机:8 cores, 64G内存, 540G SATA盘
- 数据:350万条日志,单行580B,8进程写入
测试结果:
| 指标 | Logstash | Filebeat | 对比 |
|---|---|---|---|
| CPU使用率 | 53.7% | 38.0% | Filebeat低30% |
| 处理时间 | 210秒 | 30秒 | Filebeat快7倍 |
| 收集速度 | 1.6万行/秒 | 11万行/秒 | Filebeat快7倍 |
五、EFK 完整架构(推荐生产方案)
1 | 应用服务器 → Filebeat → Kafka集群 → Logstash Indexer → Elasticsearch集群 → Kibana |
5.1 各组件职责
- Filebeat:轻量级日志收集,部署在每台应用服务器
- Kafka:消息队列,缓冲日志数据,保证可靠性
- Logstash:集中式日志处理,运行在专用服务器
- Elasticsearch:分布式存储和搜索
- Kibana:数据可视化和查询界面
5.2 配置要点
Filebeat 到 Kafka:
1 | output.kafka: |
Kafka 到 Logstash:
1 | input { |
六、实践经验与问题解决
6.1 常见问题及解决方案
| 问题 | 现象 | 解决方案 |
|---|---|---|
| Indexer 挂掉 | 日志停止消费 | 使用 Supervisor 监控进程 |
| Java异常换行 | 异常日志被分割 | 使用 multiline codec |
| 时区问题 | 日志时间差8小时 | Kibana 使用浏览器时区 |
| Grok解析失败 | 日志格式不一致 | 统一日志格式,使用在线调试 |
6.2 关键配置示例
处理多行日志:
1 | input { |
时区处理:
1 | date { |
6.3 监控与维护
- 健康检查:
1
curl -X GET "localhost:9200/_cluster/health?pretty"
- 性能监控:
- Elasticsearch:节点状态、索引速率、查询延迟
- Kafka:堆积量、消费速率
- Logstash:处理速率、错误计数
- 容量规划:
- 根据日志量预估存储需求
- 设置合理的索引生命周期策略
- 定期清理过期数据
七、总结与最佳实践
7.1 EFK 架构优势
- 高性能:Filebeat 轻量高效,Kafka 缓冲可靠
- 可扩展:各组件均可水平扩展
- 易维护:职责分离,便于问题定位
- 成本可控:根据需求灵活调整资源配置
7.2 部署建议
- 开发环境:简单版架构,快速验证
- 测试环境:集群版架构,模拟生产
- 生产环境:完整 EFK 架构,保证可靠性
7.3 未来演进方向
- 容器化部署:使用 Docker 和 Kubernetes 管理
- Serverless 架构:利用云服务简化运维
- 智能分析:结合机器学习进行异常检测
- 安全增强:日志加密、访问控制、审计追踪
7.4 成功关键因素
- 标准化:制定统一的日志格式规范
- 自动化:部署、配置、监控全流程自动化
- 文档化:完善的配置文档和操作手册
- 团队培训:确保团队成员掌握相关技能
通过从 ELK 到 EFK 的演进,我们构建了一个高性能、高可靠、易维护的日志系统。这个系统不仅解决了传统日志管理的痛点,还为业务监控、故障排查和安全审计提供了强大支持。随着技术的不断发展,日志系统将继续演进,为企业数字化转型提供更强大的数据支撑。