http://www.cnblogs.com/PatrickLiu/p/7567880.html
http://www.cnblogs.com/zhili/p/FactoryMethod.html
建造模式(Builder Pattern)
Builder,建造模式:将一个复杂对象的构建与他的表示相分离,使得同样的构建过程可以创建不同的表示。 应用场景:一个类的各个组成部分的具体实现类或者算法经常面临着变化,但是将他们组合在一起的算法却相对稳定。提供一种封装机制 将稳定的组合算法于易变的各个组成部分隔离开来。
http://www.cnblogs.com/PatrickLiu/p/7614630.html
http://www.cnblogs.com/zhili/p/BuilderPattern.html
抽象工厂(Abstract Factory)
Abstract Factory,抽象工厂:提供一个创建一系列相关或相互依赖对象的接口,而无须指定它们的具体类。 应用场景:一系列相互依赖的对象有不同的具体实现。提供一种“封装机制”来避免客户程序和这种“多系列具体对象创建工作”的紧耦合。
单例模式(Singleton Pattern)
https://www.cnblogs.com/PatrickLiu/p/8250985.html
https://www.cnblogs.com/zhili/p/SingletonPatterm.html
单例模式(Singleton):保证一个类只有一个实例,并提供一个访问它的全局访问点
应用场景:一个无状态的类使用单例模式节省内存资源。
1 |
|
私有的实例构造器是屏蔽外界的调用,上面的单例模式的实现在单线程下确实是完美的,也很好的满足了我们单线程环境的需求。
单线程单例模式的几个要点:
1.Singleton模式中的实例构造器可以设置为protected以允许子类派生。
2.Singleton模式一般不要支持ICloneable接口,因为这可能会导致多个对象实例,与Singleton模式的初衷违背。
3.Singleton模式一般不要支持序列化,因为这也有可能导致多个对象实例,同样与Singleton模式的初衷违背。
4.Singletom模式只考虑到了对象创建的工作,没有考虑对象销毁的工作。为什么这样做呢,因为Net平台是支持垃圾回收的,所以我们一般没有必要对其进行销毁处理。
5.不能应对多线程环境:在多线程环境下,使用Singleton模式仍然有可能得到Singleton类的多个实例对象
设计模式系列导航
创建型
单例模式 http://www.cnblogs.com/PatrickLiu/p/8250985.html
工厂方法模式 http://www.cnblogs.com/PatrickLiu/p/7567880.html
抽象工厂模式 http://www.cnblogs.com/PatrickLiu/p/7596897.html
建造模式 http://www.cnblogs.com/PatrickLiu/p/7614630.html
原型模式 http://www.cnblogs.com/PatrickLiu/p/7640873.html
结构型
适配器模式 http://www.cnblogs.com/PatrickLiu/p/7660554.html
桥接模式 http://www.cnblogs.com/PatrickLiu/p/7699301.html
装饰模式 http://www.cnblogs.com/PatrickLiu/p/7723225.html
组合模式 http://www.cnblogs.com/PatrickLiu/p/7743118.html
外观模式 http://www.cnblogs.com/PatrickLiu/p/7772184.html
享元模式 http://www.cnblogs.com/PatrickLiu/p/7792973.html
代理模式 http://www.cnblogs.com/PatrickLiu/p/7814004.html
行为型
模板方法 http://www.cnblogs.com/PatrickLiu/p/7837716.html
命令模式 http://www.cnblogs.com/PatrickLiu/p/7873322.html
迭代器模式 http://www.cnblogs.com/PatrickLiu/p/7903617.html
观察者模式 http://www.cnblogs.com/PatrickLiu/p/7928521.html
中介者模式 http://www.cnblogs.com/PatrickLiu/p/7928521.html
状态模式 http://www.cnblogs.com/PatrickLiu/p/8032683.html
策略模式 http://www.cnblogs.com/PatrickLiu/p/8057654.html
责任链模式 http://www.cnblogs.com/PatrickLiu/p/8109100.html
访问者模式 http://www.cnblogs.com/PatrickLiu/p/8135083.html
备忘录模式 http://www.cnblogs.com/PatrickLiu/p/8176974.html
解释器模式 http://www.cnblogs.com/PatrickLiu/p/8242238.html
面向对象的设计原则
写代码也是有原则的,我们之所以使用设计模式,主要是为了适应变化,提高代码复用率,使软件更具有可维护性和可扩展性。如果我们能更好的理解这些设计原则,对我们理解面向对象的设计模式也是有帮助的,因为这些模式的产生是基于这些原则的。这些规则是:单一职责原则(SRP)、开放封闭原则(OCP)、里氏代替原则(LSP)、依赖倒置原则(DIP)、接口隔离原则(ISP)、合成复用原则(CRP)和迪米特原则(LoD)。下面我们就分别介绍这几种设计原则。
单一职责原则(SRP):
SRP(Single Responsibilities Principle)的定义:就一个类而言,应该仅有一个引起它变化的原因。简而言之,就是功能要单一。
如果一个类承担的职责过多,就等于把这些职责耦合在一起,一个职责的变化可能会削弱或者抑制这个类完成其它职责的能力。这种耦合会导致脆弱的设计,当变化发生时,设计会遭受到意想不到的破坏。(敏捷软件开发)
软件设计真正要做的许多内容,就是发现职责并把那些职责相互分离。
小结:单一职责原则(SRP)可以看做是低耦合、高内聚在面向对象原则上的引申,将职责定义为引起变化的原因,以提高内聚性来减少引起变化的原因。责任过多,引起它变化的原因就越多,这样就会导致职责依赖,大大损伤其内聚性和耦合度。
开放关闭原则(OCP)
OCP(Open-Close Principle)的定义:就是说软件实体(类,方法等等)应该可以扩展(扩展可以理解为增加),但是不能在原来的方法或者类上修改,也可以这样说,对增加代码开放,对修改代码关闭。
OCP的两个特征: 对于扩展(增加)是开放的,因为它不影响原来的,这是新增加的。对于修改是封闭的,如果总是修改,逻辑会越来越复杂。
小结:开放封闭原则(OCP)是面向对象设计的核心思想。遵循这个原则可以为我们面向对象的设计带来巨大的好处:可维护(维护成本小,做管理简单,影响最小)、可扩展(有新需求,增加就好)、可复用(不耦合,可以使用以前代码)、灵活性好(维护方便、简单)。开发人员应该仅对程序中出现频繁变化的那些部分做出抽象,但是不能过激,对应用程序中的每个部分都刻意地进行抽象同样也不是一个好主意。拒绝不成熟的抽象和抽象本身一样重要。
里氏代替原则(LSP)
- LSP(Liskov Substitution Principle)的定义:子类型必须能够替换掉它们的父类型。更直白的说,LSP是实现面向接口编程的基础。
小结:任何基类可以出现的地方,子类一定可以出现,所以我们可以实现面向接口编程。 LSP是继承复用的基石,只有当子类可以替换掉基类,软件的功能不受到影响时,基类才能真正被复用,而子类也能够在基类的基础上增加新的行为。里氏代换原则是对“开-闭”原则的补充。实现“开-闭”原则的关键步骤就是抽象化。而基类与子类的继承关系就是抽象化的具体实现,所以里氏代换原则是对实现抽象化的具体步骤的规范。
依赖倒置原则(DIP)
DIP(Dependence Inversion Principle)的定义:抽象不应该依赖细节,细节应该依赖于抽象。简单说就是,我们要针对接口编程,而不要针对实现编程。
高层模块不应该依赖低层模块,两个都应该依赖抽象,因为抽象是稳定的。抽象不应该依赖具体(细节),具体(细节)应该依赖抽象。
小结:依赖倒置原则其实可以说是面向对象设计的标志,如果在我们编码的时候考虑的是面向接口编程,而不是简单的功能实现,体现了抽象的稳定性,只有这样才符合面向对象的设计。
接口隔离原则(ISP)
接口隔离原则(Interface Segregation Principle, ISP)指的是使用多个专门的接口比使用单一的总接口要好。也就是说不要让一个单一的接口承担过多的职责,而应把每个职责分离到多个专门的接口中,进行接口分离。过于臃肿的接口是对接口的一种污染。
使用多个专门的接口比使用单一的总接口要好。
一个类对另外一个类的依赖性应当是建立在最小的接口上的。
一个接口代表一个角色,不应当将不同的角色都交给一个接口。没有关系的接口合并在一起,形成一个臃肿的大接口,这是对角色和接口的污染。
“不应该强迫客户依赖于它们不用的方法。接口属于客户,不属于它所在的类层次结构。”这个说得很明白了,再通俗点说,不要强迫客户使用它们不用的方法,如果强迫用户使用它们不使用的方法,那么这些客户就会面临由于这些不使用的方法的改变所带来的改变。
小结:接口隔离原则(ISP)告诉我们,在做接口设计的时候,要尽量设计的接口功能单一,功能单一,使它变化的因素就少,这样就更稳定,其实这体现了高内聚,低耦合的原则,这样做也避免接口的污染。
组合复用原则(CRP)
组合复用原则(Composite Reuse Principle, CRP)就是在一个新的对象里面使用一些已有的对象,使之成为新对象的一部分。新对象通过向这些对象的委派达到复用已用功能的目的。简单地说,就是要尽量使用合成/聚合,尽量不要使用继承。
要使用好组合复用原则,首先需要区分”Has—A”和“Is—A”的关系。 “Is—A”是指一个类是另一个类的“一种”,是属于的关系,而“Has—A”则不同,它表示某一个角色具有某一项责任。导致错误的使用继承而不是聚合的常见的原因是错误地把“Has—A”当成“Is—A”.例如:鸡是动物,这就是“Is-A”的表现,某人有一个手枪,People类型里面包含一个Gun类型,这就是“Has-A”的表现。
小结:组合/聚合复用原则可以使系统更加灵活,类与类之间的耦合度降低,一个类的变化对其他类造成的影响相对较少,因此一般首选使用组合/聚合来实现复用;其次才考虑继承,在使用继承时,需要严格遵循里氏替换原则,有效使用继承会有助于对问题的理解,降低复杂度,而滥用继承反而会增加系统构建和维护的难度以及系统的复杂度,因此需要慎重使用继承复用。
迪米特法则(Law of Demeter)
迪米特法则(Law of Demeter,LoD)又叫最少知识原则(Least Knowledge Principle,LKP),指的是一个对象应当对其他对象有尽可能少的了解。也就是说,一个模块或对象应尽量少的与其他实体之间发生相互作用,使得系统功能模块相对独立,这样当一个模块修改时,影响的模块就会越少,扩展起来更加容易。
关于迪米特法则其他的一些表述有:只与你直接的朋友们通信;不要跟“陌生人”说话。
外观模式(Facade Pattern)和中介者模式(Mediator Pattern)就使用了迪米特法则。
小结:迪米特法则的初衷是降低类之间的耦合,实现类型之间的高内聚,低耦合,这样可以解耦。但是凡事都有度,过分的使用迪米特原则,会产生大量这样的中介和传递类,导致系统复杂度变大。所以在采用迪米特法则时要反复权衡,既做到结构清晰,又要高内聚低耦合。
MySQL权限管理
16个顶级计算机视觉算法库
16个顶级计算机视觉算法库 - 知乎
Excerpt
计算机识别现实世界中的物体需要用到传感器设备(例如:摄像头、声纳等),就像人类的眼睛帮助我们看到周围的世界并做出反应一样。但计算机想要识别传感器检测到的数据到底是什么物体,就需要事先使用一定的视觉算…
计算机识别现实世界中的物体需要用到传感器设备(例如:摄像头、声纳等),就像人类的眼睛帮助我们看到周围的世界并做出反应一样。但计算机想要识别传感器检测到的数据到底是什么物体,就需要事先使用一定的视觉算法对大量的数据进行训练,才能够让计算机能够识别传感器数据中所包含的物体类别并做出响应。
如今,计算机视觉在身份核验、工业、农业、医学、交通、海洋等许多行业都有广泛的用途。因此,对高质量计算机视觉库的需求也相应增加。计算机视觉库是一个预先编写好的算法代码和一些预训练好的模型或者数据。目前,在开源领域,计算机视觉库数量非常多,包括图像识别库、人脸识别库等。
以下列举了一些目前最流行的计算机视觉算法库。

1. OpenCV
https://github.com/opencv/opencv

OpenCV是迄今为止最古老也是最受欢迎的开源计算机视觉库,旨在为计算机视觉应用提供通用底层算法。
支持跨平台应用,支持Windows,Linux,Android和macOS。支持各种主流的开发语言,例如:Python,Java,C++等。OpenCV有一个Python Wrapper,支持GPU的CUDA模型。包含一些可以转换为TensorFlow模型的模型。最初由Intel开发,现在可以在开源BSD许可证下免费使用。
OpenCV的主要功能包括:
- 2D和3D图像工具包
- 人脸识别
- 手势识别
- 运动检测
- 人机交互
- 对象检测
- 图像分割和对象识别
2. Scikit-Image
https://github.com/scikit-image/scikit-image

Scikit-Image是公认的最方便的Python视觉库,它是Scikit-Learn的一个扩展库。是监督和无监督机器学习最常用的工具之一。可以用于将NumPy数组作为图像对象进行处理。
以下是使用Scikit-image进行硬币识别的例子。
1 | import skimage as ski image = ski.data.coins() # ... or any other NumPy array! edges = ski.filters.sobel(image) ski.io.imshow(edges) ski.io.show() |

3. Pillow (PIL Fork)
https://github.com/python-pillow/Pillow

Pillow是一个Python编写的图像处理库。它支持Windows、Mac OS X和Linux平台,可以在C和Python语言中使用Pillow库。主要用于阅读和保存不同格式的图像,Pillow还包括各种基本图像变换功能,例如:旋转、合并、缩放等。
4. TorchVision
https://pytorch.org/vision/stable/index.html

TorchVision是PyTorch库的一个扩展库,TorchVision拥有计算机视觉中最常见的图像转换功能,还包含计算机视觉神经网络的数据集和模型架构以及常见数据集。TorchVision旨在为方便使用PyTorch模型进行计算机视觉图像转换,而无需将图像转换为NumPy数组。TorchVision可以用于Python和C++语言开发环境。可以通过pip install将TorchVision与PyTorch库一起搭配使用。
以下是预训练分割模型的使用例子。


5. MMCV
https://github.com/open-mmlab/mmcv

MMCV是一个基于PyTorch的图像/视频处理和转换器。它支持Linux、Windows和macOS等系统,是计算机视觉研究人员最常用的包之一。支持Python和C++开发语音。
6.YOLO
https://github.com/ultralytics/ultralytics

YOLO是最快的计算机视觉工具之一,由Joseph雷德蒙和Ali Farhadi于2016年开发,专门用于实时图像对象检测。YOLO使用将神经网络,将图像划分为网格,然后同时预测每个网格,以提高识别效率。
目前YOLO已经发布V8。YOLOv8 是一款前沿、最先进(SOTA)的模型,基于先前 YOLO 版本的成功并引入了新的功能和改进,进一步提升了性能和灵活性。YOLOv8 的快速、准确且易于使用,使其成为各种对象检测与跟踪、实例分割、图像分类和姿态估计任务的绝佳选择。
7. TensorFlow

TensorFlow是由GoogleBrain团队开发并于2015年11月发布的AI框架,旨在促进构建AI模型的过程。它有一些扩展解决方案,如针对浏览器和Node.js的TensorFlow.js,以及针对终端设备的TensorFlow Lite。另外,TensorFlow还提供了一个更好的框架TensorFlow Hub。这是一个更易于使用的平台,可以使用TensorFlow Hub实现重复使用BERT和Faster R-CNN训练模型、查找可随时部署的模型、托管模型以供他人使用。
TensorFlow允许用户开发与计算机视觉相关的机器学习模型,例如:人脸识别、图像分类、目标检测等。与OpenCV一样,Tensorflow也支持各种语言,如Python、C、C++、Java或JavaScript。

8. Keras

Keras是一个基于Python的开源软件库,对初学者来说特别易用,它允许快速构建神经网络模型,是一个模块化的AI工具箱,计算机视觉工程师可以利用它来快速组装应用、训练模型。Keras的底层框架使用TensorFlow,并且拥有强大的社区支持,因此用户众多。可以使用Keras实现的内容例如:
- 图像分割和分类
- 手写识别
- 三维图像分类
- 语义图像聚类
9.MATLAB
https://ww2.mathworks.cn/products/matlab.html

MATLAB是Matrix Laboratory的缩写,但它是一个付费编程平台,适合用于如机器学习、深度学习、图像处理、视频信号处理等方面的应用,是一个受到工程师和科学家喜欢的编程平台。它配备了一个计算机视觉工具箱,包含许多算法能力,如:
- 视频目标检测与目标跟踪
- 物体识别
- 校准摄像机
- 处理三维视觉
10.NVIDIA CUDA-X
https://developer.nvidia.com/gpu-accelerated-libraries

CUDA是计算统一设备架构的首字母缩写,而NVIDIA CUDA-X是CUDA的更新版本。NVIDIA CUDA-X是一个GPU加速库和工具的集合,可以开始使用新的应用程序或GPA加速。它包含数学库、并行算法库、图像和视频库、通信库和深度学习库,可用于各种任务,例如:人脸识别、图像处理、3D图形渲染等。它兼容大多数操作系统,并且支持许多主流AI编程语言,如:C、C++、Python、Fortran、MATLAB等。
11.NVIDIA Performance Primitives
https://developer.nvidia.com/npp

CUDA(Compute Unified Device Architecture的缩写)是NVIDIA开发的并行计算平台和应用程序编程接口(API)模型。它允许开发人员使用GPU(图形处理单元)的强大功能来加快处理密集型应用程序的速度。
该工具包包含NVIDIA Performance Primitives(NPP)库,可为多个领域(包括计算机视觉)提供GPU加速的图像、视频处理和信号处理功能。此外,CUDA架构可用于各种开发任务,例如:人脸识别、图像处理、3D图形渲染等。它支持各种编程语言,包括C、C++、Python、Fortran或MATLAB,并且还与大多数操作系统兼容。
12.OpenVINO

OpenVINO是Open Visual Inference and Neural Network Optimization的缩写。它是一套非常全面的计算机视觉工具。它由英特尔开发,是一个可以免费使用的跨平台框架,具有多种视觉处理能力,包括:
- 对象检测
- 人脸识别
- 图像彩色化
- 运动识别
13.PyTorch
https://github.com/pytorch/pytorch

PyTorch是一个Python的开源机器学习框架,主要由Facebook的AI研究小组开发。在构建复杂体系结构时具有很大的灵活性。可以用于机器视觉方面开发图像评估模型、图像分割、图像分类等。
14.Caffe
https://caffe.berkeleyvision.org/
CAFFE是Convolutional Architecture for Fast Feature Embedding的缩写。是一个易于使用的开源深度学习和计算机视觉框架,由加州大学伯克利分校开发。它使用C++编写,支持多种开发语言,支持多种用于实现图像分类和图像分割的深度学习架构。Caffe可以用于视觉、语音和多媒体领域的应用,支持图像分割、分类等模型开发。
15.Detectron2
https://github.com/facebookresearch/detectron2

Detecrton 2是由Facebook AI Research(FAIR)开发的基于PyTorch的模对象检测库。Detectron 2是Detection的升级版;包括:Faster R-CNN、Mask R-CNN、RetinaNet、DensePose、Cascade R-CNN、Panoptic FPN和TensorMask等模型。Detecrton 2的功能包括:密集位姿预测、全景图像分割、联合分割、对象检测等。
16.SimpleCV

SimpleCV是一个开源免费的机器视觉框架。通这个框架,可以轻松访问OpenCV等几个高性能的计算机视觉库,而无需深入了解位深度、颜色空间、缓冲区管理或文件格式等复杂概念。
来源:andflow
2018年深度学习框架
深度学习领域发展迅猛,江湖风起云涌。在此,咪博士为大家细细盘点、比较,各大深度学习框架。也祝大家都能训出好模型,调出好参数。
以下是咪博士的观点,供大家参考:
- 如果你是初学者,那么推荐选择 Keras 或 Gluon 这样简单易用的接口入门。至于是 Keras 还是 Gluon 就不必太纠结了,因为二者都很容易上手,完全可以都学一下。如果非要分个先后的话,可以先试试 Gluon 毕竟开发者是中国人,有官方出品的中文教程带你入门。
- 学完 Keras 或 Gluon “前端”框架之后,再选择一个“后端”框架深入学习,TensorFlow (Keras 后端) 或 MXNet (Gluon 后端) 是咪博士推荐的 2 个后端框架。TensorFlow 谷歌 (Google) 出品,MXNet 有 亚马逊 (Amazon) 支持,它们都是非常优秀的深度学习框架。至于是 TensorFlow 还是 MXNet,那就得看你的需求了。TensorFlow 受众更广,但是性能较差,而且不支持动态计算图;MXNet 目前还比较小众,但性能较好,而且支持动态计算图,十分方便搞自然语言处理 (NLP) 的朋友。
- 学习完后端框架之后,你就可以非常灵活地定制自己的神经网络,自由地在深度学习的世界里翱翔了。这里候,如果你有兴趣(或需要),可以试试其他的一些框架,如 PyTorch (灵活多变,适合研究), Caffe2 (性能优化,手机也能跑), Deeplearning4j (Java 首选,整合 Hadoop, Spark), 以及 ConvNetJS (Js 开发,浏览器上玩深度学习)。
- 其他一些深度学习框架,诸如 Theano (Lasagne, 以及 Blocks), Torch, Caffe, CNTK, Chainer, Paddle, DSSTNE, DyNet, BigDL, Neon 等,由于众多原因,咪博士就不给大家推荐了。
下面是详细的比较和说明:
一、推荐使用

受到 Torch 启发,Keras 提供了简单易用的 API 接口,特别适合初学者入门。其后端采用 TensorFlow, CNTK,以及 Theano。另外,Deeplearning4j 的 Python 也是基于 Keras 实现的。Keras 几乎已经成了 Python 神经网络的接口标准。

亚马逊 (Amazon) 和 微软 (Microsoft) 于 2017 年 10 月联合推出的深度学习 API。Gluon 类似 Keras,提供了简单易用的 API 接口。但和 Keras 不一样的地方是,Gluon 还支持动态计算图(对自然语言处理特别有用)。Gluon 后端目前采用 MXNet,未来还将支持微软的 CNTK。

谷歌 (Google) 大厂出品,追随者众多。相比其他框架,TensorFlow 速度较慢,但它提供的 TensorBoard 可视化工具还是很不错的。

已被 亚马逊 (Amazon) 选为 AWS 上的深度学习框架,支持动态图计算。MXNet 有许多中国开发者,因而有非常良好的中文文档支持。Gluon 接口使得 MXNet 像 Keras 一样简单易用。
二、值得一试

背后金主是 脸书 (Facebook) ,同样支持动态计算图,提供很好的灵活性,适合研究。

同样是 脸书 (Facebook) 出品,为生产环境设计,提供在各种平台(包括移动设备)的运行时。

与其他(大多数)基于 Python 的深度学习框架不同,Deeplearning4j 基于 Java 开发,与 Hadoop, Spark 生态结合得很好。尤其令人称道的是其优秀的文档,官司方文档直接就有中文版本。另外,虽然是面向 Java 的框架,Deeplearning4j 也提供了 Python 的接口(基于 Keras 实现)

基于 Javascript 的深度学习框架,可以在浏览器中训练深度神经网络。最重要的用途是帮助学习 Deep Learning
三、不推荐
Theano, Lasagne, 以及 Blocks
Yoshua Bengio 于 2017 年 09 月宣布不再维护 Theano,所以这个项目事实上已经宣告死亡了。其他基于 Theano 的库,如 Lasagne 和 Blocks,也可以散了。
Torch
虽然设计精良(Keras 就是参考 Torch 设计的),但它基于 Lua 语言,太过小众了。而且 Facebook 已经推出了 Python 版本的 PyTorch 了。
Caffe
Caffe2 已经正式发布了,彻底取代 Caffe 只是时间问题罢了。
CNTK
微软出品,授权协议有一些特别,而且似乎也没有什么特别亮眼的地方。
Chainer
曾经是动态计算图的首选框架,特别适用于自然语言处理。但是,现在许多其他的框架,如 MXNet, PyTorch, 以及 DyNet 也支持该特性,所以 Chainer 的这一优势也就不复存在了。
Paddle
百度的深度学习框架,受众太小。
DSSTNE
曾是亚马逊的深度学习引擎,但是很小众,而且现在亚马逊又选择了 MXNet,所以 DSSTNE 的前途就更渺茫了。
DyNet
源自卡耐基梅隆大学,支持动态计算图,但是太小众了。
BigDL
Intel 基于 spark 的深度学习库,但只能运行在 Intel 芯片之上。
Neon
据说速度很快,但太过小众,而且发展还不完善,许多特性还不支持。
参考
- https://deeplearning4j.org/compare-dl4j-tensorflow-pytorch
- http://docs.chainer.org/en/stable/comparison.html
- http://www.ipaomi.com/2017/11/06/2018-年-深度学习框架-盘点-比较-推荐/
【坚信技术技术改变世界】 【欢迎学习交流】 【免费】【视频教程】【问答社区】 【爱跑咪】【http://www.iPaoMi.com】 【QQ交流: 57148911】
23种设计模式
《大话设计模式》中提到了 24种设计模式:
简单工厂模式,策略模式、装饰模式、代理模式、工厂方法模式、原型模式、模板方法模式、外观模式、建造者模式、观察者模式、抽象工厂模式、状态模式、适配器模式、备忘录模式、组合模式、迭代器模式、单例模式、桥接模式、命令模式、职责链模式、中介者模式、享元模式、解释器模式、访问者模式。
按照类型,可分为3类:
1、 创建型模式:抽象工厂、建造者模式、工厂方法、原型模式、单例模式;
创建型模式抽象了实例化的过程。创建性模式隐藏了这些类的实例是如何被创建和放在一起,整个系统关于这些对象所知道的是由抽象类所定义的接口。这样,创建性模式在创建了什么、谁创建它、她是怎么被创建的、以及何时创建方面提供了灵活性。创建相应数目的原型并克隆她们通常比每次用适合的状态手工实例化该类更方便。
2、 结构型模式:适配器模式、桥接模式、组合模式、装饰者模式、外观模式、享元模式、代理模式;
3、 行为型模式:观察者模式、模板方法、命令模式、状态模式、职责链模式、解释器模式、中介者模式、访问者模式、策略模式、备忘录模式、迭代器模式。
4、 MVC模式:集观察者、组合、策略为一体,是多种模式的综合应用,算是一种架构模式。
下面按照【概念】+【原则】+【场景】+【优点】+【缺点】+【应用】分别简述一下24种设计模式:
抽象工厂模式(Abstract Factory) 提供一个创建一系列相关或互相依赖对象的接口,而无需指定它们具体的类。
原则:LSP 里氏替换原则
场景:创建不同的产品对象,客户端应使用不同的具体工厂。
优点:
a) 改变具体工厂即可使用不同的产品配置,使改变一个应用的具体工厂变得很容易。
b) 让具体的创建实例过程与客户端分离,客户端通过抽象接口操作实例,产品的具体类名也被具体工厂的实现分离。
缺点:如果要新增方法,改动极大。
应用:
a)jdk中连接数据库的代码是典型的抽象工厂模式,每一种数据库只需提供一个统一的接口:Driver(工厂类),并实现其中的方法即可。不管是jdbc还是odbc都能够通过扩展产品线来达到连接自身数据库的方法。
b)java.util.Collection 接口中定义了一个抽象的 iterator() 方法,该方法就是一个工厂方法。对于 iterator() 方法来说 Collection 就是一个抽象工厂。
建造者模式(Builder) 【又名,生成器模式】:将一个复杂对象的构建与它的表示分离,使得同样的构建过程可以创建不同的表示。
原则:依赖倒转原则
场景:如果需要将一个复杂对象的构建与它的表示分离,使得同样的构建过程可以创建不同的表示。建造者模式是当创建复杂对象的算法应该独立于该对象的组成部分以及它们的装配方式时适用的模式。
优点:使得建造代码与表示代码分离。
缺点:1、增加代码量;2、Builder只是一个替代构造器的选择,不能直接用于降低非构造函数方法的参数数量。
应用:StringBuilder和StringBuffer的append()方法
工厂方法模式(Factory Method) 定义一个用于创建对象的接口,让子类决定实例化哪一个类,工厂方法使一个类的实例化延迟到其子类。
原则:开放封闭原则
场景:不改变工厂和产品体系,只是要扩展产品(变化)。
优点:是简单工厂模式的进一步抽象和推广,既保持了简单工厂模式的优点(工厂类中包含了必要的逻辑判断,根据客户端的选择条件动态实例化相关的类。对于客户端来说,去除了与具体产品的依赖),而且克服了简单工厂的缺点(违背了开放封闭原则)。
缺点:每增加一个产品,就需要增加一个产品工厂的类,增加了额外的开发。(用反射可以解决)。
应用:
1. Collection中的iterator方法;
2. java.lang.Proxy#newProxyInstance()
3. java.lang.Object#toString()
4. java.lang.Class#newInstance()
5. java.lang.reflect.Array#newInstance()
6. java.lang.reflect.Constructor#newInstance()
7. java.lang.Boolean#valueOf(String)
8. java.lang.Class#forName()
原型模式(prototype) 【又名,生成器模式】:用原型实例指定创建对象的种类,并且通过拷贝这些原型创建新的对象。
原则:
场景:在初始化信息不发生变化的情况,用克隆进行拷贝。
优点:隐藏了对象创建的细节,大大提升了性能。不用重新初始化对象,而是动态的获得对象运行时的状态。
缺点:深复制 or 浅复制 。
应用:JDK中的Date类。
单例模式(Singleton) 保证一个类仅有一个实例,并提供一个访问它的全局访问点。
原则:封装
场景:通常,我们可以让一个全局变量使得一个对象被访问,但它不能防止你实例化多个对象,一个最好的办法就是,让类自身负责保存它的唯一实例。这个类可以保证没有其他实例可以被创建,而且它可以提供一个访问该实例的方法。
优点:对唯一实例的受控访问。
缺点:饿汉式/懒汉式 多线程同时访问时可能造成多个实例。
应用:java.lang.Runtime; GUI中也有一些(java.awt.Toolkit#getDefaultToolkit() java.awt.Desktop#getDesktop())
适配器模式(Adapter) 将一个类的接口转换成客户希望的另外一个接口。Adapter模式使得原本由于接口不兼容而不能一起工作的那些类可以一起工作。
在GoF的设计模式中,适配器有两种类型,类适配器模式和对象适配器模式。
a) 类适配器模式:通过多重继承对一个接口与另一个接口进行匹配,而C#,Java等语言都不支持多重继承,也就是一个类只有一个父类。
b) Java一般都指的是 对象适配器模式
场景:适配器是为了复用一些现有的类。系统的数据和行为都正确,但是接口不符,这时采用适配器模式,使原有对象和新接口匹配。
优点:能够复用现存的类,客户端统一调用同一接口,更简单、直接、紧凑。
缺点:适配器模式有点儿“亡羊补牢”的感觉,设计阶段要避免使用。
应用:在Java jdk中,适配器模式使用场景很多,如集合包中Java.util.Arrays#asList()、IO包中java.io.InputStreamReader(InputStream)、java.io.OutputStreamWriter(OutputStream) 等
桥接模式(Bridge) 将抽象部分与它的实现部分分离,使它们都可以独立的变化。
原则:合成/聚合复用原则
场景:实现系统可能有多角度分类,每一种分类都有可能变化,那么就把这种多角度分离出来让它们独立变化,减少它们之间的耦合。
优点:减少各部分的耦合。 分离抽象和实现部分,更好的扩展性,可动态地切换实现、可减少子类的个数。
缺点:1、桥接模式的引入会增加系统的理解与设计难度,由于聚合关联关系建立在抽象层,要求开发者针对抽象进行设计与编程。 2、桥接模式要求正确识别出系统中两个独立变化的维度,因此其使用范围具有一定的局限性
应用:Collections类中的sort()方法;AWT;JDBC数据库访问接口API;
组合模式(Composite) 将对象组合成树形结构以表示“部分-整体”的层次结构。
场景:需求中体现部分与整体层次结构时,以及希望用户可以忽略组合对象与单个对象的不同,统一使用组合结构中的所有对象时,就应该考虑使用组合模式了。
优点:组合模式让客户可以一致的使用组合结构和单个对象。
缺点:使设计变得更加抽象,对象的业务规则如果很复杂,则实现组合模式具有很大挑战性,而且不是所有的方法都与叶子对象子类都有关联。
应用:JDK中AWT包和Swing包的设计是基于组合模式,在这些界面包中为用户提供了大量的容器构件(如Container)和成员构件(如Checkbox、Button和TextComponent等),他们都是继承、关联自抽象组件类Component。
装饰模式(Decorator) 动态地给一个对象添加一些额外的职责,就增加功能来说,装饰模式比生成子类更灵活。
场景:装饰模式是为了已有功能动态地添加更多功能的一种方式,当系统需要新功能的时候,是向旧类中添加新的代码,这些新的代码通常装饰了原有类的核心职责或主要行为。装饰着模式把每个要装饰的功能放在单独的类中,并让这个类包装它所要装饰的对象,当需要执行特殊行为时,客户代码就可以在运行时根据需要有选择的、按顺序地使用装饰功能包装对象。
优点:把类中的装饰功能从类中搬移出去,简化原有的类。有效的把类的核心职责和装饰功能区分开,去除相关类中重复的装饰逻辑。
缺点:利用装饰器模式,常常造成设计中有大量的小类,数量实在太多,可能会造成使用此API程序员的困扰。
应用:Java I/O使用装饰模式设计,JDK中还有很多类是使用装饰模式设计的,如:Reader类、Writer类、OutputStream类等。
外观模式(facade) 为子系统中的一组接口提供一个一致的界面,此模式定义了一个高层接口,这个接口使得这一子系统更加容易使用。
原则:完美的体现了依赖倒转原则和迪米特法则。
场景:
a) 设计阶段:需有意识的将不同的两个层分离。
b) 开发阶段:增加外观façade提供一个简单的接口,应对子类的重演和演化。
c) 维护期间:使用façade类,为遗留代码提供清晰简单的接口,让新系统与façade交互,façade与遗留代码交互所有复杂的工作。
优点:1、客户对子系统的使用变得简单了,减少了与子系统的关联对象,实现了子系统与客户之间的松耦合关系。 2、只是提供了一个访问子系统的统一入口,并不影响用户直接使用子系统类 3、降低了大型软件系统中的编译依赖性,并简化了系统在不同平台之间的移植过程。
缺点:1、不能很好地限制客户使用子系统类,如果对客户访问子系统类做太多的限制则减少了可变性和灵活性 2、在不引入抽象外观类的情况下,增加新的子系统可能需要修改外观类或客户端的源代码,违背了“开闭原则”。
享元模式(Flyweight) 运用共享技术有效的支持大量细粒度的对象。
场景:如果一个应用程序使用了大量的对象,而大量的这些对象造成了很大存储开销时就应该考虑使用享元模式;还有就是对象大多数状态都可为外部状态,如果删除对象的外部状态,那么可以用相对较少的共享对象取代很多组对象,此时可以考虑使用享元模式。
优点:享元模式可以避免大量非常相似类的开销。程序中,大量细粒度的类实例来表示数据,如果它们除了几个参数外基本相同,那么把它们转移到类实例的外面,在方法调用时将它们传递进来,就可以通过共享大幅度减少单个实例的数目。
缺点:1、由于享元模式需要区分外部状态和内部状态,使得应用程序在某种程度上来说更加复杂化了。2、为了使对象可以共享,享元模式需要将享元对象的状态外部化,而读取外部状态使得运行时间变长。
应用:String 类。
代理模式(proxy) 为其他对象提供一种代理以控制对这个对象的访问。
原则:代理模式就是在访问对象时引入一定程度的间接性。(迪米特法则?)
场景:
a) 远程代理:为一个对象在不同的地址空间提供局部代表,这样可以隐藏一个对象存在于不同地址空间的事实。【WebService,客户端可以调用代理解决远程访问问题】
b) 虚拟代理:根据需要创建开销很大的对象,通过它来存放实例化需要很长时间地真实对象。【比如Html网页的图片,代理存储的是真实图片的路径和尺寸】
c) 安全代理:用来控制真实对象的访问权限。
d) 智能指引:当调用真实的对象时,代理处理另一些事。【如计算机真实对象的引用次数,代理在访问一个对象的时候回附加一些内务处理,检查对象是否被锁定、是否该释放、是否该装入内存等等】
优点:1)代理模式能将代理对象与真正被调用的对象分离,在一定程度上降低了系统的耦合度。2)代理模式在客户端和目标对象之间起到一个中介作用,这样可以起到保护目标对象的作用。代理对象也可以对目标对象调用之前进行其他操作。
缺点:1)在客户端和目标对象增加一个代理对象,会造成请求处理速度变慢。2)增加了系统的复杂度。
应用:java.lang.reflect 包中的Proxy类和InvocationHandler 接口提供了生成动态代理类的能力。
观察者模式(Publish/Subscribe) 【又名 发布-订阅模式】:定义了一种一对多的依赖关系,让多个观察者对象同时监听某一个主题对象。这个主题对象在状态发生变化时,会通知所有观察者对象,让它们能够自动更新自己。
场景:将一个系统分割成一系列互相协作的类,有一个缺点:需要维护相关对象间的一致性。紧密的耦合会给维护和扩展带来不便。观察者模式就是为了解耦而诞生的,让原本一个对象依赖另一个对象的关系,变成了两方都依赖于抽象,而不再依赖于具体,从而使得各自的变化都不会影响另一边的变化。
优点:解耦。
缺点:如果在被观察者之间有循环依赖的话,被观察者会触发它们之间进行循环调用,导致系统崩溃。在使用观察者模式是要特别注意这一点。
应用:java.util.Observer , java类库实现观察着(Observer)模式的类和接口。
模板方法模式(Template Method) 定义一个操作中的算法的骨架,而将一些步骤延迟到子类中。
原则:代码复用平台。
场景:遇到由一系列步骤构成的过程需要执行,这个过程从高层次上看是相同的,但是有些步骤的实现可能不同,这个时候就需要考虑用模板方法模式了。
优点:模板方法模式是通过把不变行为搬移到超类,去除子类中重复代码来实现它的优势,提供了一个代码复用平台,帮助子类摆脱重复的不变行为的纠缠。
缺点:如果父类中可变的基本方法太多,将会导致类的个数增加,系统更加庞大。
应用:AbstractClass抽象类里面的TemplateMethod()就是模板方法。
命令模式(command) 将一个请求封装为一个对象,从而使你可用不同的请求对客户进行参数化;对请求排队或记录请求日志,以及支持可撤销的操作。
原则:敏捷开发原则
场景:对请求排队或记录请求日志,以及支持可撤销的操作等行为。
优点:
a) 命令模式把请求一个操作的对象与知道怎么执行一个操作的对象分割开。
b) 它能较容易的设计一个命令队列。
c) 在需要的情况下,可以较容易的将命令记入日志。
d) 允许接收请求的一方决定是否要否决请求。
e) 可以容易的实现对请求的撤销和重做。
f) 由于加进新的具体命令类不影响其他类,因此增加新的具体命令类很容易。
缺点:会增加系统的复杂性,这里的复杂性应该主要指的是类的数量。
应用:
1. java.util.Timer类中scheduleXXX()方法
2. java Concurrency Executor execute()方法
3. java.lang.reflect.Methodinvoke()方法
状态模式(state) 当一个对象的内在状态改变时,允许改变其行为,这个对象看起来像是改变了其类。
原则:单一职责原则
场景:当一个对象的行为取决于它的状态,并且它必须在运行时刻根据状态改变它的行为时,可以考虑使用状态模式了。
优点:状态模式主要解决的是当控制一个对象状态转换的条件表达式过于复杂的情况。把状态的判断逻辑转移到表示不同状态的一系列类当中,可以把复杂的判断逻辑简化。【消除庞大的条件分支语句】。
缺点:违背开放-封闭原则
应用:
1. java.util.Iterator
2. javax.faces.lifecycle.LifeCycle#execute()
职责链模式(chain of responsibility) 使多个对象都有机会处理请求,从而避免请求的发送者和接受者之间的耦合关系。将这个对象连成一条链,并沿着这条链传递该请求,直到有一个对象处理它为止。
场景:当客户提交一个请求时,请求是沿链传递直至有一个对象负责处理它。
优点:使得接收者和发送者都没有对方的明确信息,且链中对象自己也不知道链结构,结果是职责链可以简化对象的相互连接,它们只需要保持一个指向其后继者的引用,而不需要保持它所有的候选接收者的引用。开发者可以随时的增加或者修改处理一个请求的结构,增强了给对象指派职责的灵活性。
缺点:一个请求极有可能到了链的末端都得不到处理,或者因为没有正确配置而得不到处理。
解释器模式(interpreter) 给定一个语言,定义它的文法的一种表示,并定义一个解释器,这个解释器使用该表示来解释语言中的句子。
原则:依赖倒转原则
场景:如果一种特定类型问题发生的频率足够高,那么可能就值得将该问题的各个实例表述为一个简单语句中的句子。这样就可以构建一个解释器,该解释器通过解释这些句子来解决该问题。当一个语言需要执行,并且你可将该语言中的句子表示为一个抽象语法树时,可以用解释器模式。
优点:解释器很容易改变和扩展文法,因为该模式使用类来表示文法规则,可以使用继承来改变或扩展文法,也比较容易实现文法。因为定义抽象语法树中各个节点的类的实现大体类似,这些类都易于直接编写。
缺点:解释器模式为文法中的每一条规则至少定义了一个类,因此包含许多规则的文法可能难以管理和维护,建议当文法非常复杂时,使用其他技术(语法分析程序、编译器生成器)。
应用:
1. java.util.Pattern
2. java.text.Normalizer
3. java.text.Format
4. javax.el.ELResolver
中介者模式(mediator) 用一个中介对象来封装一系列的对象交互。中介者使各对象不需要显示的相互引用,从而使其耦合松散,而且可以独立的改变它们之间的交互。
场景:一般应用于一组对象以定义良好但是复杂的方式进行通信的场合,以及想定制一个分布在多个类的行为,而又不想生成太多子类的场合。【例如,Form窗体,或者aspx页面】。
优点:
a) 抽象中介者类(Mediator)减少了抽象同事类(colleague)之间的耦合,是的可以独立的改变和复用各个类。
b) 由于把对象如何协作进行了抽象,将中介作为一个独立的概念并将其封装在一个对象中,这样关注的对象就从对象各自本身的行为转移到它们之间的交互上来,也就是站在一个更宏观的角度去看待系统。
缺点:控制集中化导致了中介者的复杂化。
应用:
1. java.util.Timer
2. java.util.concurrent.Executor#execute()
3. java.util.concurrent.ExecutorService#submit()
4. java.lang.reflect.Method#invoke()
访问者模式 (Vistor) 生成器模式】:(GoF中最复杂的一个模式)表示一个作用于某对象结构中的各元素的操作,它使你可以在不改变各元素的类的前提下定义作用于这些元素的新操作。
场景:访问者模式适合有稳定的数据结构、又有易于变化的算法】访问者模式适用于数据结构相对稳定的系统,它把数据结构和作用于结构上的操作之间的耦合解脱开,是的操作集合可以相对自由的演化。访问者模式的目的是要把处理从数据结构中分离出来。
优点:增加新的操作很容易。新的操作就是新的访问者。
缺点:很难增加新的数据结构。
应用:
1. javax.lang.model.element.AnnotationValue和AnnotationValueVisitor
2. javax.lang.model.element.Element和ElementVisitor
3. javax.lang.model.type.TypeMirror和TypeVisitor
策略模式(strategy) 它定义了算法家族,分别封装起来,让它们之间可以互相替换,此模式让算法的变化不会影响到使用算法的用户。
场景:策略模式不仅可以用来封装算法,几乎可以封装缝合类型的规则,不同的业务逻辑都可以考虑用策略模式处理变化。
优点:策略模式的策略类为上下文定义了一系列可供重用的算法或行为,继承有助于析取出这些算法中的公共功能。另外,策略模式简化了单元测试,因为每一个算法都有自己的类,可以通过自己的接口单独测试。当不同的行为堆砌在一个类中,很难避免使用switch语句。但是将这些行为封装在一个一个独立的策略类中,可以在使用这些行为的类中消除条件语句
缺点:基本的策略模式,选择权在客户端,具体实现转给策略模式的上下文对象。这并不好。使用策略模式和工厂类结合,可以减轻客户端的职责。但是还是不够完美,使用反射才能真正快乐。
应用:
1. java.util.Comparator#compare()
2. javax.servlet.http.HttpServlet
3. javax.servlet.Filter#doFilter()
备忘录模式(Memento) 在不破坏封装性的前提下,捕获一个对象的内部状态,并在该对象之外保存这个状态,这样以后就可将该对象恢复到原先保存的状态。
场景:Memento封装要保存的细节,适合功能负责但需要维护或记录属性历史的类,或者是需要保存的属性只是众多属性中的一个小部分。
优点:使用备忘录模式可以把复杂的发起人内部信息对其他的对象屏蔽起来,从而可以恰当地保持封装的边界。
缺点:如果发起人角色的状态需要完整地存储到备忘录对象中,那么在资源消耗上面备忘录对象会很昂贵。
应用:
1. java.util.Date
2. java.io.Serializable
迭代器模式(Iterator) 提供一种方法顺序访问一个聚合对象中各个元素,而又不暴露该对象的内部表示。
场景:当需要对聚集有多种方式遍历时,可以考虑使用迭代器。
优点:迭代器模式就是分离了集合对象的遍历行为,抽象出一个迭代器来负责,这样既可以做到不暴露集合的内部结构,又可以让外部代码透明的访问集合内部的数据。
缺点:由于迭代器模式将存储数据和遍历数据的职责分离,增加新的聚合类需要对应增加新的迭代器类,类的个数成对增加,这在一定程度上增加了系统的复杂性。
应用:collection容器使用了迭代器模式
设计模式在JDK的应用:http://blog.csdn.net/u013782203/article/details/52214393
38款流媒体服务器开源软件
http://www.oschina.net/project/tag/111/streaming?lang=0&os=0&sort=view&p=1
Flash流媒体服务器 Red5
Red5是一个采用Java开发开源的Flash流媒体服务器。它支持:把音频(MP3)和视频(FLV)转换成播放流; 录制客户端播放流(只支持FLV);共享对象;现场直播流发布;远程调用。Red5使用RSTP作为流媒体传输协议,在其自带的一些示例中演示了在线录制,flash…
 更多Red5信息
更多Red5信息最近更新: Red5 1.0.1 Final 发布,Flash流媒体服务器 发布于 12个月前
流媒体服务器 Open Streaming Server
Open Streaming Server (Catra Streaming Platform) 是一个数字媒体传送器,主要功能包括支持 mp4、3gp、WMF和qt文件格式;动态带宽适配;负载均衡、内容分发技术。基于 C++、Java 和 CORBA 技术开发。… 更多Open Streaming Server信息
流媒体解决方案 live555
Live555 是一个为流媒体提供解决方案的跨平台的C++开源项目,它实现了对标准流媒体传输协议如RTP/RTCP、RTSP、SIP等的支持。Live555实现了对多种音视频编码格式的音视频数据的流化、接收和处理等支持,包括MPEG、H.263+、DV、JPEG视频和多种音频编码。同时… 更多live555信息
Darwin Streaming Server
Darwin Streaming Server 使用开放标准,让你可以透过互联网实时传送实况或预先录制的内容。在 Instant-On——苹果电脑公司正在申请专利的一项创新流媒体播送技术的支持下,你的内容将在点击链接的同时开始播放,无需等待文件下载。…
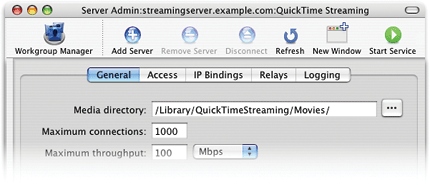 更多Darwin Streaming Server信息
更多Darwin Streaming Server信息【商业】流媒体服务器软件 Helix Server
Helix Server是由著名的流媒体技术服务商Real Networks公司提供的一种流媒体服务器软件,利用它可以在 网上提供Real Video和MMS格式文件的流媒体播放服务,配上相应设备后,还具有现场直播的功能。下面介绍一下有关Helix服务器的获取、安装、运行管理和使用…
 更多Helix Server信息
更多Helix Server信息开源流媒体平台 FreeCast
MPEG4IP
MPEG4IP提供一个端对端的系统来实现音视频流的传输,支持包括MPEG4/H.261/MPEG2/H.263 MP3/AAC/AMR等不同编码格式。
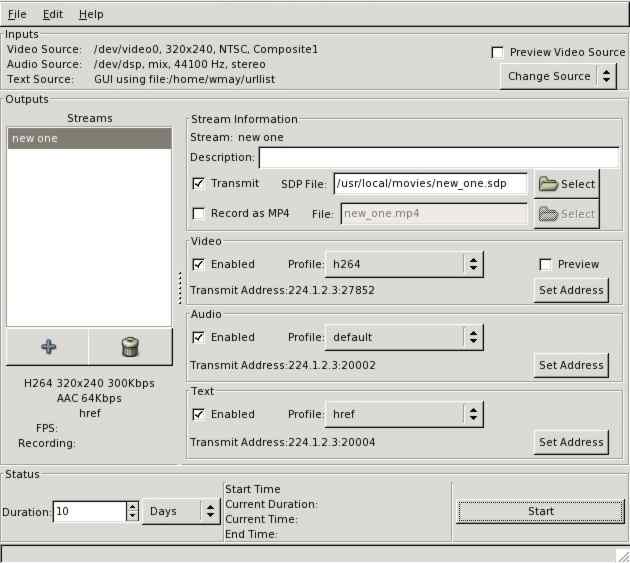 更多MPEG4IP信息
更多MPEG4IP信息开源流媒体平台 Stream-2-Stream
Stream-2-Stream 是一个用 Java 语言实现的 Multicast+ 下一代流媒体传输协议。与传统的流媒体技术相比较,Multicast+ 具有更高效的传输效率和更少的带宽占用。 主要特点: Integrated MP3, Ogg media player. No external media player needed to listen!… 更多Stream-2-Stream信息
流媒体服务器 Yass
Yass是一个基于Web的流媒体服务器(streaming server),拥有一个类似于iTunes的界面。它能够共享你的MP3音乐库,并通过Internet访问。Yass利用JPA(openJpa)操 作数据,spring控制事务。利用Apache Derby来存储数据。通过JAX-RS与JAXB(Jersey)实现客户端…
 更多Yass信息
更多Yass信息流媒体服务器 Flumotion
Flumotion 是一个前卫的(modern)的流媒体服务器,采用模块化分布式的设计理念,提供您稳定及高质量的流媒体服务. Flumotion 支持 Ogg/Theora也支持 MPEG-4 等格式,使用者不必一次下载所有的文件就能在线观看媒体播放的结果。 Flumotion 提供了一个基于 Ja…
 更多Flumotion信息
更多Flumotion信息Java实现的RTMP Flazr
Flazr 是一个实现了 RTMP 流媒体传输协议的 Java 类库,该项目包含一个流媒体服务器和相关的工具。 更多Flazr信息
【商业】流媒体服务器 xmoovStream
xmoovStream是一个采用PHP开发的开源流媒体服务器,能够将视频、图片、音频转成可以在网页上播放的流媒体。这个服务器还自带轻量级视频播放 器和音频播放器。
 更多xmoovStream信息
更多xmoovStream信息NGINX的流媒体插件 nginx-rtmp-module
战斗民族俄罗斯人民开发的一款NGINX的流媒体插件,除了直播发布音视频流之外具备流媒体服务器的常见功能 比如推拉流媒体资源 基于HTTP的FLV/MP4 VOD点播 HLS (HTTP Live Streaming) M3U8的支持 基于http的操作(发布、播放、录制) 可以很好的协同现有的流… 更多nginx-rtmp-module信息
icecast
icecast 是一套开放源码 (Open Source) 的流媒体服务器软件 (Streaming Server), 支持 MP3 与 Ogg Vorbis 流格式, 串流資料則由其他支援 icecast 的 Source Clients (或稱 Streamer) 提供. 例如: ices 將電腦中的 MP3 檔案轉成串流資料 darkice 將音效卡的… 更多icecast信息
RTMP流媒体服务器 crtmpserver
crtmpserver又称rtmpd是Evostream Media Server(www.evostream.com)的社区版本采用GPLV3授权 其主要作用为一个高性能的RTMP流媒体服务器,可以实现直播与点播功能多终端支持功能,在特定情况下是FMS的良好替代品。 支持RTMP的一堆协议(RTMP,RTMPE, RTM… 更多crtmpserver信息
Free UPnP Entertainment Service
流媒体服务器 Slyseal
Slyseal 是一个使用Python编写的轻量级可扩展的流媒体服务器,实现了Adobe RTMP 协议,支持h.264编码的视频。 这里是演示 http://www.orakili.org. 更多Slyseal信息
电视流媒体服务器 Tvheadend
Combined DVB reciever, Digital Video Recorder and Showtime streaming server for Linux. Tvheadend 是一个流媒体服务器/中继supporing多种渠道和多种输出格式。它主要是用于接收电视(广播,模拟IPTV )和将其转交使用了一些不同的输出格式的用户。加上… 更多Tvheadend信息
webcamFLV
webcamFLV 是 Windows 下的摄像头软件,可以将视频和声音数据流转换为Flash FLV格式以便在 Web上发布,使用实时视频编码器ffMpeg进行开发。 更多webcamFLV信息
WEB自动点唱机 netjukebox
netjukebox是一个php开发的基于Web的自动点唱机。 更多的屏幕截图请看:http://www.netjukebox.nl/screenshot.php 演示地址:http://www.netjukebox.nl/demo.php[](http://www.oschina.net/p/netjukebox “netjukebox”) 更多netjukebox信息
Java流媒体服务器 JRoar
JRoar 是一个纯 Java 开发的Ogg 流媒体服务器。It casts live Ogg streams to Ogg Vorbis players as IceCast2 does and shouts live Ogg streams to IceCast2 and JRoar. JRoar also accepts live Ogg streams from Ices. The uniqueness of JRoar is tha… 更多JRoar信息
OpenAMF
OpenAMF 项目是免费的开放源码替代Macromedia的远程Java Flash. 这是因为能够提供作为应用服务,以Flash MX的大媒体的专有解决方案. 这个项目开始作为一个java AMF-PHP接口. 更多OpenAMF信息
多媒体传输协议库 oRTP
RTP(Real-timeTransportProtocol)是用于Internet上针对多媒体数据流的一种传输协议,做流媒体传输方面的应 用离不开RTP协议的实现及使用,为了更加快速地在项目中应用RTP协议实现流媒体的传输,我们一般会选择使用一些RTP库,例如使用c++语言编写的 JRTP… 更多oRTP信息
Helix DNA Platform
The Helix DNA Server is a universal delivery engine supporting the real time packetization and network transmission of any media type to any device. The Helix DNA Server is the industry’s core media delivery engine and should be at the c… 更多Helix DNA Platform信息
流媒体服务器 Tunapie
Tunapie,一个可以自动从网络上下载网络电台和视频流媒体的列表软件。在Windows下用过WinAMP的用户应该都有印象WinAMP有一个可以从网络更新列表,用户可以选择电台或视频流媒体。Tunapie就是WinAMP这个功能的独立软件,当然是For linux的。 要播放Tunapie…
 更多Tunapie信息
更多Tunapie信息家庭视频直播和分享 xShow@Home
注:xShow@Home 已经改名为 xDisplayAtHome ,项目页面更改至 https://code.google.com/p/xdisplay/ xShow@Home 是我开发的视频平台xShow的一个分支,用于家庭视频直播和分享,可将一个视频(电影或摄像头采集的视频)在PC、Mac、Linux、Android上同时播…
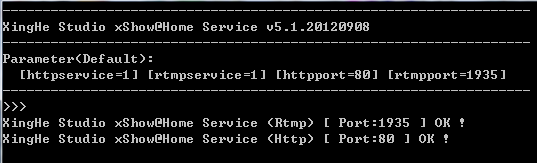 更多xShow@Home信息
更多xShow@Home信息最近更新: xShow@Home v5.1.20120908 发布 发布于 1年前
流媒体服务器 TivoServer
TivoServer 是一个通过家庭多媒体服务将 PC 中的视频输出到 Tivo 的解决方案,目前需要对 Tivo 进行破解,并且只支持那些先前从 Tivo 解压出来的版本。
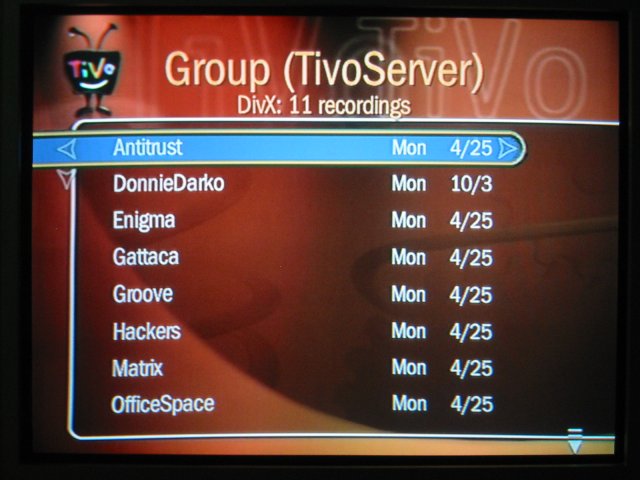 更多TivoServer信息
更多TivoServer信息Mobicents Multimedia Server
MMS (Mobicents Multimedia Server) 是一个基于 Java 开发的实时媒体服务器,提供流媒体、会议、录制、回放、IVR、TTS 等多项多媒体功能,可通过 MGCP 或者媒体控制(JSR 309) 驱动进行访问。 该项目继承自 Mobicents Media Server… 更多Mobicents Multimedia Server信息
最近更新: Mobicents Multimedia Server 3.0 RC2 发布 发布于 10个月前
m3w网站的流媒体服务器 m3w
m3w 是 www.m3w.com 网站所使用的音乐流媒体服务器,通过捕捉来自声卡的数据并转换成流媒体进行播放,提供高质量、高可靠性和易用的流媒体工具。
 更多m3w信息
更多m3w信息pulpTunes
pulpTunes是一个为 iTunes 桌面软件提供的一个 Web 服务器,通过它你可以在 Web 上访问 iTunes 中的音乐。采用 Java 开发,支持各种操作系统。你可以安装在你的机器上来访问你的iTunes音乐库,可以在世界任何地方通过网络浏览器,跟你的朋友和家人分享你的音…
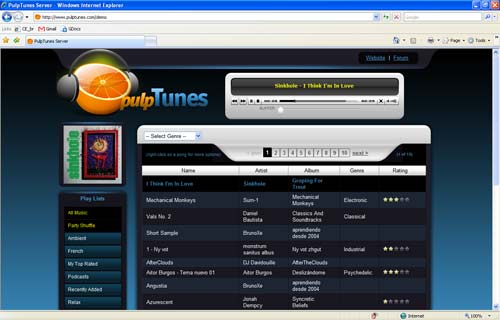 更多pulpTunes信息
更多pulpTunes信息音频流记录器 DarkIce
DarkIce便是一个实时的音频流记录器。它支持从音频接口,例如音效卡录制音频信息并进行编码后将其发送到流媒体服务器。 DarkIce可以记录从OSS音频设备,ALSA音频设备,Solaris 音频接口,和 Jack 音源。 DarkIce可以编码成MP3,MP2方法,Ogg Vorbis和AAC格…更多DarkIce信息
最近更新: DarkIce 1.2 发布,增加对 Ogg/Opus 的支持 发布于 5个月前
Tin Can Jukebox
Tin Can Jukebox 是一个快速、功能全面的基于Web的 jukebox ,可安全的输出很大的 MP3 集合数据流。提供包括浏览模型、动态下载、播放列表、语言包、用户访问控制等功能。 在线演示: http://www.tincanjukebox.com/demo/index.php...[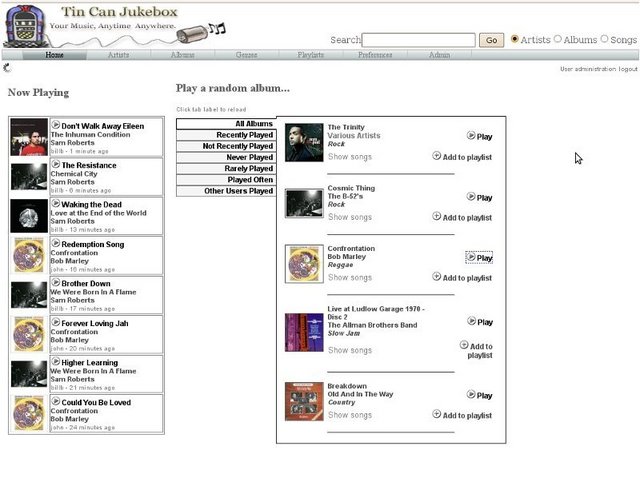](http://www.oschina.net/p/tincanjukebox “Tin Can Jukebox”) 更多Tin Can Jukebox信息
RTMFP服务器脚本 CumulusServer
openrtmfp又名Cumulus Server是一个完全开源和跨平台的可扩展的RTMFP服务器脚本。Cumulus Server在GPL 框架下遵循速度、优势、跨平台、轻量和高质量代码。Cumulus Server的每一个版本都是通过严格测试和审核的。可通过Cumulus官网费下载源代码并编译安装。…更多CumulusServer信息
RTMP/HLS 直播服务器 simple-rtmp-server
一个采用MIT协议授权的国产的简单的RTMP/HLS 直播服务器,其核心的价值理念在于简单高效。 使用方法: tep 1: build srs tar xf simple-rtmp-server-*.*.tar.gzcd simple-rtmp-server-*.*/trunk./configure –with-ssl –with-hlsmake step 2: start … 更多simple-rtmp-server信息
开源流媒体服务器 Feng
Feng是LSCUBE维护的开源流媒体服务器,兼容IETF标准,实现了RTSP、RTP/RTCP。 Feng支持的编码标准: 音频: MPEG Audio (MPEG-1/2 Layer I/II/III) (rfc2250) Vorbis (draft) AAC (MPEG-4 Part 3) (rfc3640) 视频: MPEG Video (MPEG-1/2) (rfc2250) MPEG… 更多Feng信息
DVB-C 调制器 mptsd
mptsd 从 UDP/多播 或者是 HTTP 接收 MPEGTS 流,并将这些数据库合并到一个多程序流,特别适合输出 DVB-C 调制器。 It has been tested with the Dektec DTE-3114 Quad QAM Modulator and it is used in production in couple of small DVB-C networks…. 更多mptsd信息
流媒体服务器 Babylon
babylon ======= 巴比伦流媒体服务器,目前只支持rtmp协议 #如何使用# ``` package main import ( “babylon/rtmp” log “github.com/cihub/seelog” “runtime” ) func main() { runtime.GOMAXPROCS(runtime.NumCPU()) l := “:1935” err := r… 更多Babylon信息
m9u
m9u 是一个类似于 MPD 和 XMMS2 的音乐服务器软件。 更多m9u信息