现在成熟的ORM比比皆是,这里只介绍Dapper的使用(最起码我在使用它,已经运用到项目中,小伙伴们反馈还可以)。
优点:
1、开源、轻量、小巧、上手容易。
2、支持的数据库还蛮多的, Mysql,SqlLite,Sqlserver,Oracle等一系列的数据库。
3、Dapper原理通过Emit反射IDataReader的序列队列来快速的得到和产生对象。性能貌似很牛逼的样子
缺点:
作为一款ORM太过于轻量级了,根据对象自动生成sql的功能还是空白,需要自己来扩展,
当然这也是优点, 好声音的导师们经常说某人就是张白纸……
因此针对Dapper已经有很多成熟的扩展项目了,Dapper.Rainbow、Dapper.Contrib,DapperExtensions。
我们这里介绍的是DapperExtensions。
dapper-dot-net源码:https://github.com/StackExchange/dapper-dot-net (更新频率快,项目包含了各种除了Dapper-Extensions的 扩展项目)
Dapper-Extensions 源码:https://github.com/tmsmith/Dapper-Extensions
Dapper-Extensions的优点:
1、开源
2、针对Dapper封装了常用的CRUD方法,有独立的查询语法。
3、需要映射的实体类本身0配置,无需加特性什么的。是通过独立的映射类来处理,可以设置类映射到DB的别名,字段的别名等等。
Dapper-Extensions的缺点:
1、好几年没更新了
2、不支持oracle(木有oracle的方言,已经搞定)
3、不能同时支持多种数据库(已经搞定)
4、部分代码有些bug(发现的都搞定了)
下面先简单介绍一下Dapper的基本语法。
Dapper就一个.cs文件,可以放到项目代码中直接编译,也可以直接引用DLL文件。
Dapper对DB的操作依赖于Connection,为了支持多库,咱们用 IDbConnection conn
using (IDbConnection conn = GetConnection())
{ const string query = “select * from XO order by id desc”; return conn.Query
}
下面是带参数的语法

int xoID=666; //变量主键
using (IDbConnection conn = GetConnection())
{ const string query = “select * from XO where Id=@MyID”; return conn.Query
}
各种方法都重载了事务的操作,一般的数据库操作都支持。但是每次执行都需要传递sql,而且每次都要使用Using,看着不爽啊, 这……
好吧下面简单介绍下使用Dapper-Extensions的基本语法(在Dapper-Extensions 的基础上用了Repository模式,代码效果如下)。
//实体类
DemoEntity entity = new DemoEntity(); //根据实体主键删除
this.Delete<DemoEntity>(entity); //根据主键ID删除
this.Delete<DemoEntity>(1); //增加
this.Insert<DemoEntity>(entity); //更新
bool result = this.Update<DemoEntity>(entity); //根据主键返回实体
entity = this.GetById<DemoEntity>(1); //返回 行数
this.Count<DemoEntity>(new { ID = 1 }); //查询所有
IEnumerable<DemoEntity> list = this.GetAll<DemoEntity>();
IList<ISort> sort = new List<ISort>();
sort.Add(new Sort { PropertyName = "ID", Ascending = false }); //条件查询
list = this.GetList<DemoEntity>(new { ID = 1, Name = "123" }, sort); //orm 拼接条件 查询
IList<IPredicate> predList = new List<IPredicate>();
predList.Add(Predicates.Field<DemoEntity>(p => p.Name, Operator.Like, "不知道%"));
predList.Add(Predicates.Field<DemoEntity>(p => p.ID, Operator.Eq, 1));
IPredicateGroup predGroup \= Predicates.Group(GroupOperator.And, predList.ToArray());
list \= this.GetList<DemoEntity>(predGroup); //分页查询
long allRowsCount = 0; this.GetPageList<DemoEntity>(1, 10, out allRowsCount, new { ID = 1 }, sort);
在说ORM之前,还是要说一下HY.DataAccess这个模块

这个模块是对数据访问提供的一个Helper的功能,里面包含了 各种DB的SqlHelper,分页。
DBHelper 都继承自IDBHelper.cs

using System.Data.Common; using System.Data; namespace HY.DataAccess
{ ///
/// 提供对数据库的基本操作,连接字符串需要在数据库配置。 ///
public interface IDBHelper
{ ///
/// 生成分页SQL语句 ///
///
///
///
///
///
///
string GetPagingSql(int pageIndex, int pageSize, string selectSql, string sqlCount, string orderBy); ///
/// 开始一个事务 ///
///
DbTransaction BeginTractionand(); ///
/// 开始一个事务 ///
/// 数据库连接字符key
DbTransaction BeginTractionand(string connKey); ///
/// 回滚事务 ///
/// 要回滚的事务
void RollbackTractionand(DbTransaction dbTransaction); ///
/// 结束并确认事务 ///
/// 要结束的事务
void CommitTractionand(DbTransaction dbTransaction); #region DataSet
/// <summary>
/// 执行sql语句,ExecuteDataSet 返回DataSet /// </summary>
/// <param name="commandText">sql语句</param>
/// <param name="commandType"></param>
DataSet ExecuteDataSet(string commandText, CommandType commandType); /// <summary>
/// 执行sql语句,ExecuteDataSet 返回DataSet /// </summary>
/// <param name="connKey">数据库连接字符key</param>
/// <param name="commandText">sql语句</param>
/// <param name="commandType"></param>
DataSet ExecuteDataSet(string connKey, string commandText, CommandType commandType); /// <summary>
/// 执行sql语句,ExecuteDataSet 返回DataSet /// </summary>
/// <param name="commandText">sql语句</param>
/// <param name="commandType"></param>
/// <param name="parameterValues">参数</param>
DataSet ExecuteDataSet(string commandText, CommandType commandType, params DbParameter\[\] parameterValues); /// <summary>
/// 执行sql语句,ExecuteDataSet 返回DataSet /// </summary>
/// <param name="connKey">数据库连接字符key</param>
/// <param name="commandText">sql语句</param>
/// <param name="commandType"></param>
/// <param name="parameterValues">参数</param>
DataSet ExecuteDataSet(string connKey, string commandText, CommandType commandType, params DbParameter\[\] parameterValues); #endregion
#region ExecuteNonQuery
/// <summary>
/// 执行sql语句,返回影响的行数 /// </summary>
/// <param name="commandText">sql语句</param>
/// <param name="commandType"></param>
int ExecuteNonQuery(string commandText, CommandType commandType); /// <summary>
/// 执行sql语句,返回影响的行数 /// </summary>
/// <param name="connKey">数据库连接字符key</param>
/// <param name="commandText">sql语句</param>
/// <param name="commandType"></param>
int ExecuteNonQuery(string connKey, string commandText, CommandType commandType); /// <summary>
/// 执行sql语句,返回影响的行数 /// </summary>
/// <param name="trans">事务对象</param>
/// <param name="commandText">sql语句</param>
/// <param name="commandType"></param>
int ExecuteNonQuery(DbTransaction trans, string commandText, CommandType commandType); /// <summary>
/// 执行sql语句,返回影响的行数 /// </summary>
/// <param name="commandText">sql语句</param>
/// <param name="commandType"></param>
/// <param name="parameterValues">参数</param>
int ExecuteNonQuery(string commandText, CommandType commandType, params DbParameter\[\] parameterValues); /// <summary>
/// 执行sql语句,返回影响的行数 /// </summary>
/// <param name="connKey">数据库连接字符key</param>
/// <param name="commandText">sql语句</param>
/// <param name="commandType"></param>
/// <param name="parameterValues">参数</param>
int ExecuteNonQuery(string connKey, string commandText, CommandType commandType, params DbParameter\[\] parameterValues); /// <summary>
/// 执行sql语句,返回影响的行数 /// </summary>
/// <param name="trans">事务对象</param>
/// <param name="commandText">sql语句</param>
/// <param name="commandType"></param>
/// <param name="parameterValues">参数</param>
int ExecuteNonQuery(DbTransaction trans, string commandText, CommandType commandType, params DbParameter\[\] parameterValues); #endregion
#region IDataReader
/// <summary>
/// 执行sql语句,ExecuteReader 返回IDataReader /// </summary>
/// <param name="commandText">sql语句</param>
/// <param name="commandType"></param>
IDataReader ExecuteReader(string commandText, CommandType commandType); /// <summary>
/// 执行sql语句,ExecuteReader 返回IDataReader /// </summary>
/// <param name="commandText">sql语句</param>
/// <param name="commandType"></param>
/// <param name="parameterValues">参数</param>
IDataReader ExecuteReader(string commandText, CommandType commandType, params DbParameter\[\] parameterValues); /// <summary>
/// 执行sql语句,ExecuteReader 返回IDataReader /// </summary>
/// <param name="connKey">数据库连接字符key</param>
/// <param name="commandText">sql语句</param>
/// <param name="commandType"></param>
IDataReader ExecuteReader(string connKey, string commandText, CommandType commandType); /// <summary>
/// 执行sql语句,ExecuteReader 返回IDataReader /// </summary>
/// <param name="connKey">数据库连接字符key</param>
/// <param name="commandText">sql语句</param>
/// <param name="commandType"></param>
/// <param name="parameterValues">参数</param>
IDataReader ExecuteReader(string connKey, string commandText, CommandType commandType, params DbParameter\[\] parameterValues); #endregion
#region ExecuteScalar
/// <summary>
/// 执行sql语句,ExecuteScalar 返回第一行第一列的值 /// </summary>
/// <param name="commandText">sql语句</param>
/// <param name="commandType"></param>
object ExecuteScalar(string commandText, CommandType commandType); /// <summary>
/// 执行sql语句,ExecuteScalar 返回第一行第一列的值 /// </summary>
/// <param name="commandText">sql语句</param>
/// <param name="commandType"></param>
/// <param name="parameterValues">参数</param>
object ExecuteScalar(string commandText, CommandType commandType, params DbParameter\[\] parameterValues); /// <summary>
/// 执行sql语句,ExecuteScalar 返回第一行第一列的值 /// </summary>
/// <param name="trans">事务</param>
/// <param name="commandText">sql语句</param>
/// <param name="commandType"></param>
object ExecuteScalar(DbTransaction trans, string commandText, CommandType commandType); /// <summary>
/// 执行sql语句,ExecuteScalar 返回第一行第一列的值 /// </summary>
/// <param name="connKey">数据库连接字符key</param>
/// <param name="commandText">sql语句</param>
/// <param name="commandType"></param>
object ExecuteScalar(string connKey, string commandText, CommandType commandType); /// <summary>
/// 执行sql语句,ExecuteScalar 返回第一行第一列的值 /// </summary>
/// <param name="connKey">数据库连接字符key</param>
/// <param name="commandText">sql语句</param>
/// <param name="commandType"></param>
/// <param name="parameterValues">参数</param>
object ExecuteScalar(string connKey, string commandText, CommandType commandType, params DbParameter\[\] parameterValues); /// <summary>
/// 执行sql语句,ExecuteScalar 返回第一行第一列的值 /// </summary>
/// <param name="trans">事务</param>
/// <param name="commandText">sql语句</param>
/// <param name="commandType"></param>
/// <param name="parameterValues">参数</param>
/// <returns></returns>
object ExecuteScalar(DbTransaction trans, string commandText, CommandType commandType, params DbParameter\[\] parameterValues); #endregion }
}
View Code
IDBSession.cs 对数据访问对象的定义
using System; using System.Data; namespace HY.DataAccess
{ ///
/// 数据库接口 ///
public interface IDatabase
{
IDbConnection Connection { get; }
DatabaseType DatabaseType { get; } string ConnKey { get; }
} /// <summary>
/// 数据库类对象 /// </summary>
public class Database : IDatabase
{ public IDbConnection Connection { get; private set; } public DatabaseType DatabaseType { get; private set; } public string ConnKey { get; set; } public Database(IDbConnection connection)
{
Connection \= connection;
} public Database(DatabaseType dbType, string connKey)
{
DatabaseType \= dbType;
ConnKey \= connKey;
Connection \= SqlConnectionFactory.CreateSqlConnection(dbType, connKey);
}
} /// <summary>
/// 数据连接事务的Session接口 /// </summary>
public interface IDBSession : IDisposable
{ string ConnKey { get; }
DatabaseType DatabaseType { get; }
IDbConnection Connection { get; }
IDbTransaction Transaction { get; }
IDbTransaction Begin(IsolationLevel isolation \= IsolationLevel.ReadCommitted); void Commit(); void Rollback();
}
}
View Code
SqlConnectionFactory.cs 这个类是采用工厂模式创建DB连接的封装,代码如下:
using System; using System.Collections.Generic; using System.Configuration; using System.Data; namespace HY.DataAccess
{ public enum DatabaseType
{
SqlServer,
MySql,
Oracle,
DB2
} public class SqlConnectionFactory
{ public static IDbConnection CreateSqlConnection(DatabaseType dbType, string strKey)
{
IDbConnection connection = null; string strConn = ConfigurationManager.ConnectionStrings[strKey].ConnectionString; switch (dbType)
{ case DatabaseType.SqlServer:
connection = new System.Data.SqlClient.SqlConnection(strConn); break; case DatabaseType.MySql: //connection = new MySql.Data.MySqlClient.MySqlConnection(strConn); //break;
case DatabaseType.Oracle: //connection = new Oracle.DataAccess.Client.OracleConnection(strConn);
connection = new System.Data.OracleClient.OracleConnection(strConn); break; case DatabaseType.DB2:
connection = new System.Data.OleDb.OleDbConnection(strConn); break;
} return connection;
}
}
}
View Code
ORM也不是万能的,比如做大数据的批量插入什么的,还是需要SqlHelper,加上有的人就喜欢DataTable或者DataSet。
所以SqlHelper作为根基,ORM作为辅助,万无一失啊。
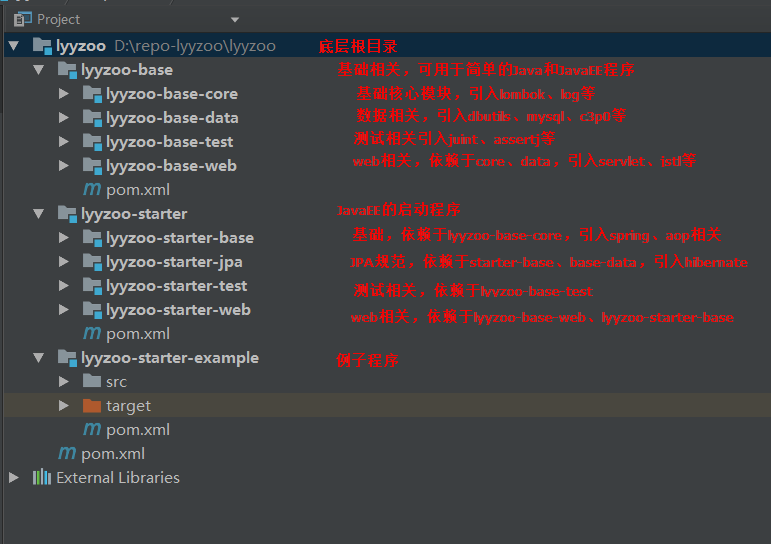
下面说说ORM这块的实现方式。见下截图

IDataServiceRepository.cs(提供业务层使用,里面的方法不支持传递sql,包含sql的语句最好还是放在数据层操作的好)
using System.Collections.Generic; using System.Data; using DapperExtensions; using HY.DataAccess; namespace HY.ORM
{ public interface IDataServiceRepository
{
IDBSession DBSession { get; }
T GetById<T>(dynamic primaryId) where T : class;
IEnumerable<T> GetByIds<T>(IList<dynamic> ids) where T : class;
IEnumerable<T> GetAll<T>() where T : class; int Count<T>(object predicate, bool buffered = false) where T : class; //lsit
IEnumerable<T> GetList<T>(object predicate = null, IList<ISort> sort = null, bool buffered = false) where T : class;
IEnumerable<T> GetPageList<T>(int pageIndex, int pageSize, out long allRowsCount, object predicate = null, IList<ISort> sort = null, bool buffered = true) where T : class;
dynamic Insert<T>(T entity, IDbTransaction transaction = null) where T : class; bool InsertBatch<T>(IEnumerable<T> entityList, IDbTransaction transaction = null) where T : class; bool Update<T>(T entity, IDbTransaction transaction = null) where T : class; bool UpdateBatch<T>(IEnumerable<T> entityList, IDbTransaction transaction = null) where T : class; int Delete<T>(dynamic primaryId, IDbTransaction transaction = null) where T : class; int DeleteList<T>(object predicate, IDbTransaction transaction = null) where T : class; bool DeleteBatch<T>(IEnumerable<dynamic> ids, IDbTransaction transaction = null) where T : class;
}
}
View Code
IDataRepository.cs(提供数据层使用,继承了上面的IDataServiceRepository,支持传入sql)
using System; using System.Collections.Generic; using System.Data; using Dapper; using HY.DataAccess; namespace HY.ORM
{ public interface IDataRepository : IDataServiceRepository
{
IDBSession DBSession { get; }
IEnumerable<T> Get<T>(string sql, dynamic param = null, bool buffered = true) where T : class;
IEnumerable<dynamic> Get(string sql, dynamic param = null, bool buffered = true);
IEnumerable<TReturn> Get<TFirst, TSecond, TReturn>(string sql, Func<TFirst, TSecond, TReturn> map,
dynamic param \= null, IDbTransaction transaction = null, bool buffered = true, string splitOn = "Id", int? commandTimeout = null);
IEnumerable<TReturn> Get<TFirst, TSecond,TThird, TReturn>(string sql, Func<TFirst, TSecond,TThird, TReturn> map,
dynamic param \= null, IDbTransaction transaction = null, bool buffered = true, string splitOn = "Id", int? commandTimeout = null);
SqlMapper.GridReader GetMultiple(string sql, dynamic param = null, IDbTransaction transaction = null, int? commandTimeout = null, CommandType? commandType = null);
IEnumerable<T> GetPage<T>(int pageIndex, int pageSize, out long allRowsCount, string sql, dynamic param = null, string allRowsCountSql=null, dynamic allRowsCountParam = null, bool buffered = true) where T : class;
Int32 Execute(string sql, dynamic param = null, IDbTransaction transaction = null);
}
}
View Code
RepositoryServiceBase.cs(IDataServiceRepository的实现类)
using System.Collections.Generic; using System.Data; using System.Linq; using Dapper; using DapperExtensions; using HY.DataAccess; namespace HY.ORM
{ public class RepositoryServiceBase : IDataServiceRepository
{ public RepositoryServiceBase()
{
} public RepositoryServiceBase(IDBSession dbSession)
{
DBSession = dbSession;
} public IDBSession DBSession { get; private set; } public void SetDBSession(IDBSession dbSession)
{
DBSession = dbSession;
} ///
/// 根据Id获取实体 ///
///
///
///
public T GetById
} ///
/// 根据多个Id获取多个实体 ///
///
///
///
public IEnumerable
IEnumerable
} ///
/// 获取全部数据集合 ///
///
///
public IEnumerable
} ///
/// 统计记录总数 ///
///
///
///
///
public int Count
} ///
/// 查询列表数据 ///
///
///
///
///
///
public IEnumerable
} ///
/// 分页 ///
///
///
///
///
///
///
///
///
public IEnumerable
{
sort = new List
}
IEnumerable
allRowsCount = DBSession.Connection.Count
} ///
/// 插入单条记录 ///
///
///
///
///
public dynamic Insert
dynamic result = DBSession.Connection.Insert
} ///
/// 更新单条记录 ///
///
///
///
///
public bool Update
} ///
/// 删除单条记录 ///
///
///
///
///
public int Delete
} ///
/// 删除单条记录 ///
///
///
///
///
public int DeleteList
} ///
/// 批量插入功能 ///
///
///
///
public bool InsertBatch
{
Insert
}
isOk = true; return isOk;
} ///
/// 批量更新() ///
///
///
///
///
public bool UpdateBatch
{
Update
}
isOk = true; return isOk;
} ///
/// 批量删除 ///
///
///
///
///
public bool DeleteBatch
{
Delete
}
isOk = true; return isOk;
}
}
}
View Code
RepositoryBase.cs(IDataRepository的实现类)
using System; using System.Collections.Generic; using System.Data; using Dapper; using DapperExtensions; using HY.DataAccess; namespace HY.ORM
{ ///
/// Repository基类 ///
public class RepositoryBase : RepositoryServiceBase, IDataRepository
{ public RepositoryBase()
{
} public new void SetDBSession(IDBSession dbSession)
{ base.SetDBSession(dbSession);
} public RepositoryBase(IDBSession dbSession)
: base(dbSession)
{
} ///
/// 根据条件筛选出数据集合 ///
///
///
///
///
///
public IEnumerable
} ///
/// 根据条件筛选数据集合 ///
///
///
///
///
public IEnumerable
{ return DBSession.Connection.Query(sql, param as object, DBSession.Transaction, buffered);
} ///
/// 分页查询 ///
///
///
///
///
///
///
///
///
///
///
public IEnumerable
IEnumerable
} ///
/// 根据表达式筛选 ///
///
///
///
///
///
///
///
///
///
///
///
public IEnumerable
dynamic param = null, IDbTransaction transaction = null, bool buffered = true, string splitOn = “Id”, int? commandTimeout = null)
{ return DBSession.Connection.Query(sql, map, param as object, transaction, buffered, splitOn);
} ///
/// 根据表达式筛选 ///
///
///
///
///
///
///
///
///
///
///
///
public IEnumerable
dynamic param = null, IDbTransaction transaction = null, bool buffered = true, string splitOn = “Id”, int? commandTimeout = null)
{ return DBSession.Connection.Query(sql, map, param as object, transaction, buffered, splitOn);
} ///
/// 获取多实体集合 ///
///
///
///
///
///
///
public SqlMapper.GridReader GetMultiple(string sql, dynamic param = null, IDbTransaction transaction = null, int? commandTimeout = null, CommandType? commandType = null)
{ return DBSession.Connection.QueryMultiple(sql, param as object, transaction, commandTimeout, commandType);
} ///
/// 执行sql操作 ///
///
///
///
public int Execute(string sql, dynamic param = null, IDbTransaction transaction = null)
{ return DBSession.Connection.Execute(sql, param as object, transaction);
}
}
}
View Code
说起DapperExtensions修改的小地方还蛮多的,下图是一个代码比较的截图。所以一会把代码打包贴上来吧(见文章结尾)。

上述代码就可以编译成 HY.ORM.DLL文件了。
下面就可以在 自己业务层继承HY.ORM中的RepositoryServiceBase类 ,数据层继承HY.ORM中的 RepositoryBase类。
通过各自的构造函数或者, SetDBSession(Helper.CreateDBSession()); 进行数据连接初始化。
接下来配置实体类和DB的映射:
public class DemoEntity
{ public int ID { get; set; } public string Name { get; set; }
}
\[Serializable\] public class DomoEntityORMMapper : ClassMapper<DemoEntity> { public DomoEntityORMMapper()
{ base.Table("Demo"); //Map(f => f.UserID).Ignore();//设置忽略 //Map(f => f.Name).Key(KeyType.Identity);//设置主键 (如果主键名称不包含字母“ID”,请设置)
AutoMap();
}
}
这样就可以在类中 实现 this.Get
具体的使用方发
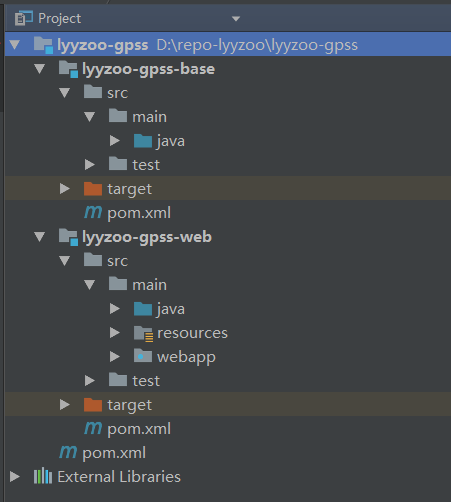
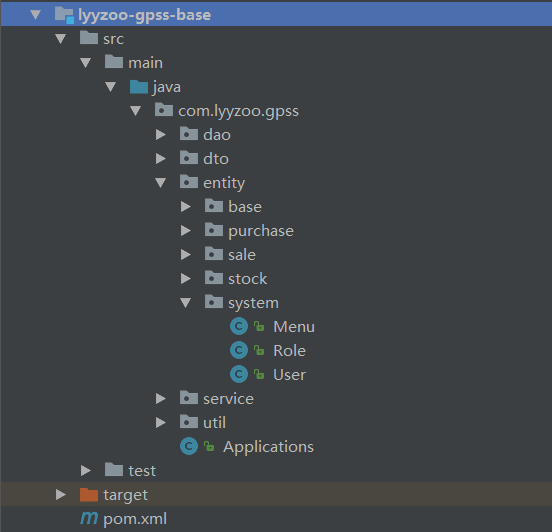
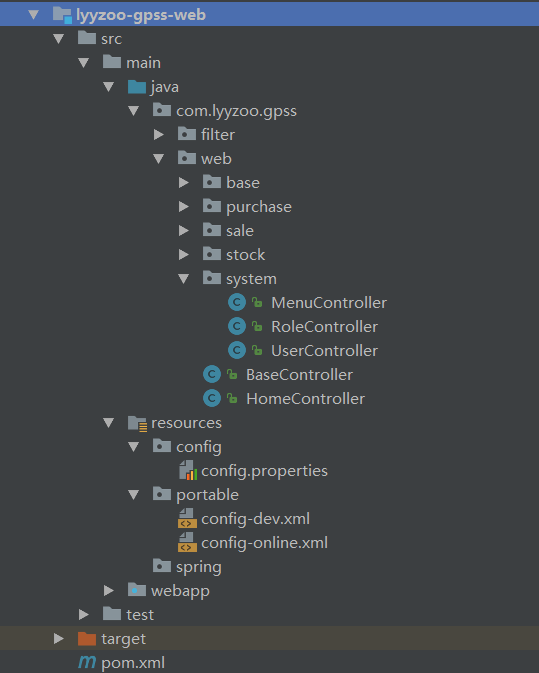
下图是我要介绍实现的项目截图:

其实也是三层,只是名字不一样而已。
HY.Web( UI层,MVC)
HY.Web.Iservice( 服务接口层)
HY.Web.Service(服务层,HY.Web.Iservice的实现类, 你也可以理解为业务逻辑层BLL)
HY.Web.DAO(数据访问层, 你也可以理解为DAL)
HY.Web.Entity(实体层, 目前只定义了数据实体, 如果你的系统需要给app提供数据, 那么传输的数据要精简,就需要单独定义DTO了。 )
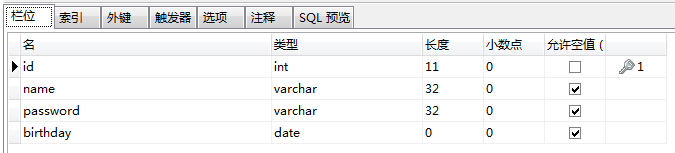
就那用户表来做个实例吧,表结构如下:(下图是用代码生成器截图效果,可以直接修改数据库的描述信息,开发利器。需要的朋友点这里【CodeBuilder-RazorEngine】)

HY.Web.Entity
在HY.Web.Entity的项目中新建Sys_UsersEntity.cs 定义实体类
View Code
HY.Web.DAO
定义基类 BaseRepository.cs (可以设置默认的DBsession,方便扩展其它东东)
View Code
定义数据访问层 Sys_UsersRepository.cs (代码里可以封装任何需要写sql 的代码)
View Code
HY.Web.IService
定义接口 ISys_UsersService.cs ,提供给UI访问。
View Code
HY.Web.Service
定义BaseService.cs,(可以设置默认的DBsession,方便扩展其它东东)
View Code
定义Sys_UsersService.cs, 去实现ISys_UsersService。
View Code
HY.Web
1、定义相关的Controller
2、ISys_UsersService iSys_UsersService = new Sys_UsersService(); (这块其实可以使用 IoC, 相关内容且听后续分解)
3、调用接口
View Code
下载:
修改后的DapperExtensions:**Dapperextensions.RAR**
_ps:已经更新版本了, 加入了对lambda的扩展,点击这里进入
_
相关文章:
搭建一套自己实用的.net架构(2)【日志模块-log4net】
搭建一套自己实用的.net架构(3)【ORM-Dapper+DapperExtensions】
搭建一套自己实用的.net架构(3)续 【ORM Dapper+DapperExtensions+Lambda】