Hexo 博客配置
环境准备
本地安装 Git NodeJS
检查环境
1 | git -v |
切换镜像站,具体参考NPM配置国内源
1 | npm config set registry https://registry.npmmirror.com |
Hexo环境搭建
1 | pnpm install -g hexo-cli # 安装Hexo cli工具 |
Hexo 配置
参考官方文档
1 | ... |
注意: 评论部分需要借助Github Discussions, 参考Hexo博客配置Giscus评论
Hexo主题配置
安装主题后从npm_modules/<主题名>/文件夹中复制_config.yml到博客根目录并重命名为_config.next.yml,当博客deploy时回自动应用主题配置,一下主题修改都基于此文件进行。
设置语言
NexT主题支持多种语言,只需要编辑_config.next.yml中的language设置即可
| 语言 | 代码 | 设定示例 |
|---|---|---|
| English | en | language: en |
| 简体中文 | zh-CN(注:zh-Hans已经无法使用) | language: zh-CN |
| Frangais | fr-FR | language: fr-FR |
| Portugues | pt | language: pt 或者 language:pt-BR |
| 繁體中文 | zh-hk 或者 zh-tw |
language: zh-hk |
| Pycckmi 93bIK | ru | language: ru |
| Deutsch | de | language: de |
| 日本語 | ja | language: ja |
| Indonesian | id | language: id |
| Korean | ko | language: ko |
如果需要添加非内置的字段需要手动添加翻译文件,例如中文的翻译文件路径为node_modules/next/languages/zh-CN.yml |
设置关于
在source/about/index.md中添加如下内容
1 | --- |
选择Scheme
Scheme 是 NexT 提供的一种特性,借助于 Scheme,NexT 为你提供多种不同的外观。同时,几乎所有的配置都可以 在 Scheme 之间共用。目前 NexT 支持三种 Schem
- Muse - 默认 Scheme
- Mist - Muse 的紧凑版本
- Pisces - 双栏 Scheme
- Gemini
菜单配置
菜单配置包括三个部分,第一是菜单项(名称和链接),第二是菜单项的显示文本,第三是菜单项对应的图标。 NexT 使用的是 Font Awesome 提供的图标, Font Awesome 提供了 600+ 的图标,可以满足绝大的多数的场景,同时无须担心在 Retina 屏幕下 图标模糊的问题。
1 | menu: home: / || home |
NexT 默认的菜单项有(标注 * 的项表示需要手动创建这个页面):
注意: 若站点运行在子目录中,请将链接前缀的 / 去掉。
| 键值 | 设定值 | 显示文本(简体中文) |
|---|---|---|
| home | home: / | 主页 |
| archives | archives: /archives | 归档页 |
| categories | categories: /categories | 分类页 * |
| tags | tags: /tags | 标签页 * |
| about | about: /about | 关于页面* |
| commonweal | commonweal: /404.html | 公益 404 ! |
侧栏配置
默认情况下,侧栏仅在文章页面(拥有目录列表)时才显示,并放置于右侧位置。配置具体如下
1 | ... |
侧栏显示位置支持
left: 居左显示right: 居右显示
侧栏显示行为支持
post默认行为,在文章页面(拥有目录列表)时显示always所有页面都显示hide在所有页面中都隐藏(可以手动展开)remove完全移除
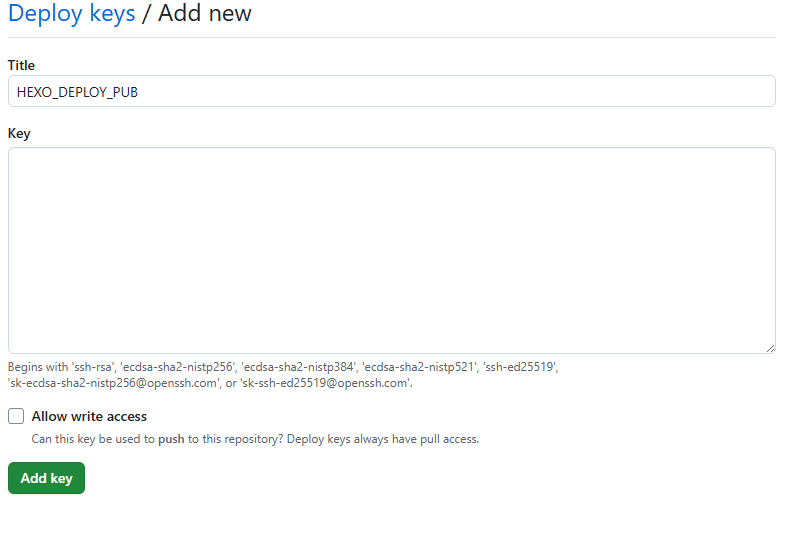
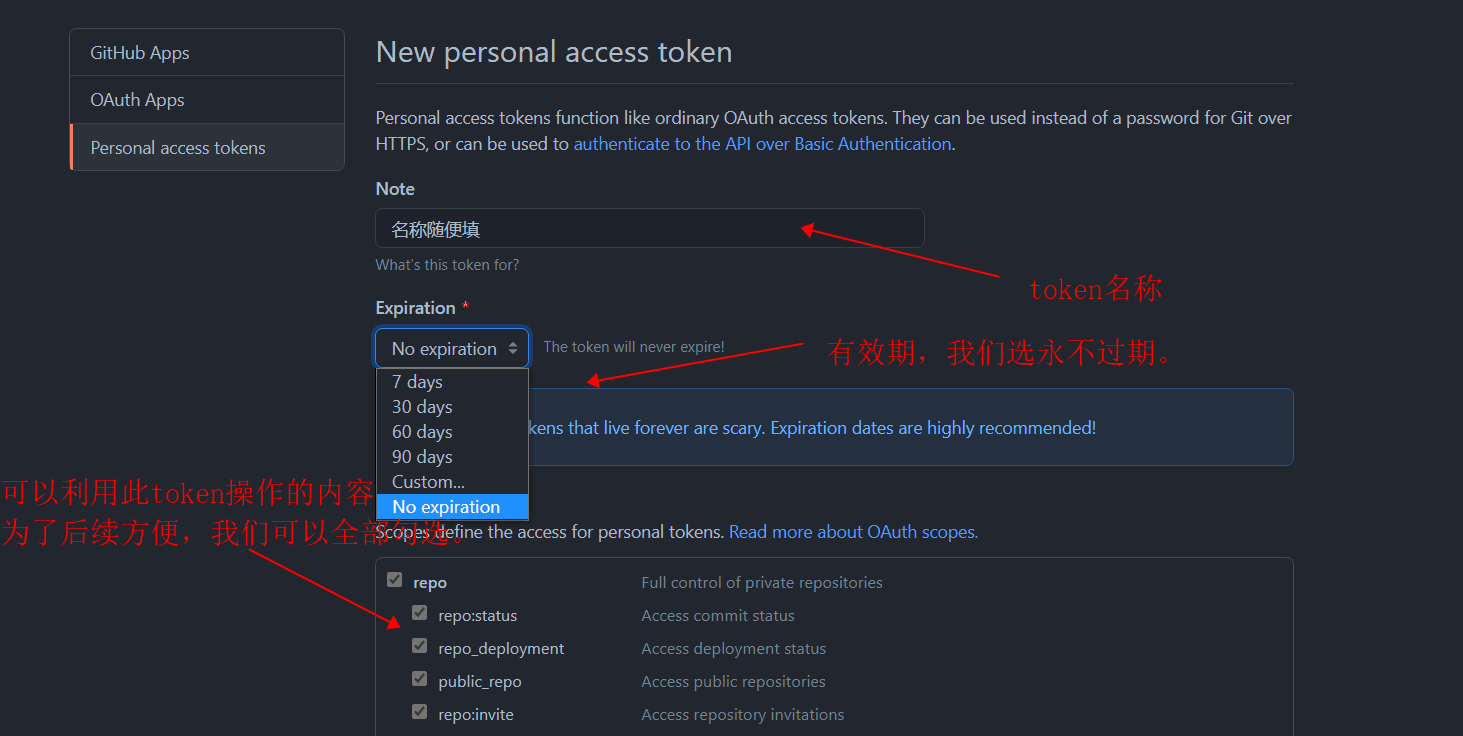
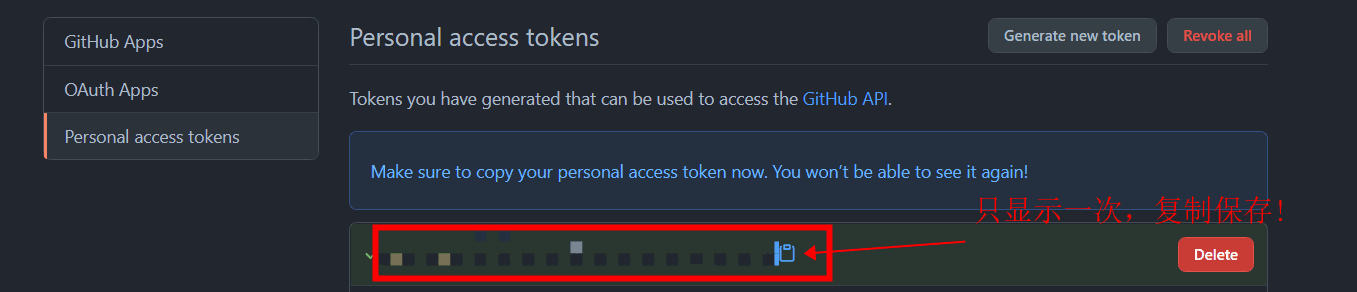
注册Github账号,Gitea账号(可选)
[^注] Github由于网络问题会经常无法链接,可使用Gitea作为中转,先将代码提交道Gitea,然后Gitea配置自动推送到Github
设置头像
1 | avatar: /images/avatar.jpg |
头像地址如果是以/起始则表示头像图片放置在博客发布后的目录下,例如测试博客地址是http://localhost:4000,头像图片地址为http://localhost:4000/images/avatar.jpg
此配置需要在博客的source/images目录中放置头像图片avatar.jpg
侧边栏社交链接
1 | social: |
next主题默认支持的社交链接 ||符号后是链接的图标
使用已有配置放开注释即可,如果要添加默认不存在链接示例如下
1 | social: |
注意: 图标对应的名称是FontAwesom图标的名称(不必带 fa- 前缀)
打赏功能
1 | # Reward |
放开此部分注释并在source/images中放入收款码图片
站点建立时间
1 | footer: |
订阅微信公众号
1 | # Wechat Subscriber |
放开此部分注释,并在source/images中放入公众号二维码
注意: 此功能需要NexT版本在5.0.1之后
设置动画
NexT 默认开启动画效果,效果使用 JavaScript 编写,因此需要等待 JavaScript 脚本完全加载完毕后才会显示内容。 如果您比较在乎速度,可以将设置此字段的值为 false 来关闭动画。
1 | # Use velocity to animate everything. |
设置全文阅读
在首页显示一篇文章的部分内容,并提供一个链接跳转到全文页面是一个常见的需求。 NexT 提供三种方式来控制文章在首页的显示方式。
- 在文章中使用
<!-- more -->手动进行截断,Hexo 提供的方式 推荐。 - 在文章的 front-matter 中添加 description,并提供文章摘录
- 自动形成摘要,需要添加如下配置
1
2
3
4
5# Automatically Excerpt. Not recommend.
# Please use <!-- more --> in the post to control excerpt accurately.
auto_excerpt:
enable: true
length: 150
设置字数统计/阅读时长
在_config.yml中配置如下
1 | # Post wordcount display settings |
加载进度条
1 | # Progress bar in the top during page loading. |
搜索服务
在_config.yml中配置如下
1 | # hexo-generator-searchdb |
在_config.next.yml中配置如下
1 | # Local search |