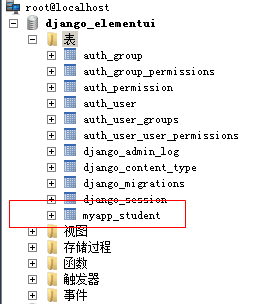
ByteBufferNetty中ByteBuffer的介绍Netty 的数据处理 API 通过两个组件暴露——abstract class ByteBuf 和 interfaceByteBufHolderDotNetty中有AbstractByteBuffer IByteBuffer IByteBufferHolder优点:它可以被用户自定义的缓冲区类型扩展;通过内置的复合缓冲区…
ByteBuffer
Netty中ByteBuffer的介绍
Netty 的数据处理 API 通过两个组件暴露——abstract class ByteBuf 和 interface ByteBufHolder
# The values in this file override the default values used by the system if # a config option is not specified. The commented out lines are the configuration # field and the default value used. Uncommenting a line and changing the value # will change the value used at runtime when the process is restarted.
# Once every 24 hours InfluxDB will report usage data to usage.influxdata.com # The data includes a random ID, os, arch, version, the number of series and other # usage data. No data from user databases is ever transmitted. # Change this option to true to disable reporting. # reporting-disabled = false
# Bind address to use for the RPC service for backup and restore. # bind-address = "127.0.0.1:8088"
### ### [meta] ### ### Controls the parameters for the Raft consensus group that stores metadata ### about the InfluxDB cluster. ###
[meta] # Where the metadata/raft database is stored dir = "D:/influxdb-1.4.2-1/meta"
# Automatically create a default retention policy when creating a database. retention-autocreate = true
# If log messages are printed for the meta service logging-enabled = true
### ### [data] ### ### Controls where the actual shard data for InfluxDB lives and how it is ### flushed from the WAL. "dir" may need to be changed to a suitable place ### for your system, but the WAL settings are an advanced configuration. The ### defaults should work for most systems. ###
[data] # The directory where the TSM storage engine stores TSM files. dir = "D:/influxdb-1.4.2-1/data"
# The directory where the TSM storage engine stores WAL files. wal-dir = "D:/influxdb-1.4.2-1/wal"
# The amount of time that a write will wait before fsyncing. A duration # greater than 0 can be used to batch up multiple fsync calls. This is useful for slower # disks or when WAL write contention is seen. A value of 0s fsyncs every write to the WAL. # Values in the range of 0-100ms are recommended for non-SSD disks. # wal-fsync-delay = "0s"
# The type of shard index to use for new shards. The default is an in-memory index that is # recreated at startup. A value of "tsi1" will use a disk based index that supports higher # cardinality datasets. # index-version = "inmem"
# Trace logging provides more verbose output around the tsm engine. Turning # this on can provide more useful output for debugging tsm engine issues. # trace-logging-enabled = false
# Whether queries should be logged before execution. Very useful for troubleshooting, but will # log any sensitive data contained within a query. query-log-enabled = true
# Settings for the TSM engine
# CacheMaxMemorySize is the maximum size a shard's cache can # reach before it starts rejecting writes. # Valid size suffixes are k, m, or g (case insensitive, 1024 = 1k). # Vaues without a size suffix are in bytes. # cache-max-memory-size = "1g"
# CacheSnapshotMemorySize is the size at which the engine will # snapshot the cache and write it to a TSM file, freeing up memory # Valid size suffixes are k, m, or g (case insensitive, 1024 = 1k). # Values without a size suffix are in bytes. # cache-snapshot-memory-size = "25m"
# CacheSnapshotWriteColdDuration is the length of time at # which the engine will snapshot the cache and write it to # a new TSM file if the shard hasn't received writes or deletes # cache-snapshot-write-cold-duration = "10m"
# CompactFullWriteColdDuration is the duration at which the engine # will compact all TSM files in a shard if it hasn't received a # write or delete # compact-full-write-cold-duration = "4h"
# The maximum number of concurrent full and level compactions that can run at one time. A # value of 0 results in 50% of runtime.GOMAXPROCS(0) used at runtime. Any number greater # than 0 limits compactions to that value. This setting does not apply # to cache snapshotting. # max-concurrent-compactions = 0
# The maximum series allowed per database before writes are dropped. This limit can prevent # high cardinality issues at the database level. This limit can be disabled by setting it to # 0. # max-series-per-database = 1000000
# The maximum number of tag values per tag that are allowed before writes are dropped. This limit # can prevent high cardinality tag values from being written to a measurement. This limit can be # disabled by setting it to 0. # max-values-per-tag = 100000
### ### [coordinator] ### ### Controls the clustering service configuration. ###
[coordinator] # The default time a write request will wait until a "timeout" error is returned to the caller. # write-timeout = "10s"
# The maximum number of concurrent queries allowed to be executing at one time. If a query is # executed and exceeds this limit, an error is returned to the caller. This limit can be disabled # by setting it to 0. # max-concurrent-queries = 0
# The maximum time a query will is allowed to execute before being killed by the system. This limit # can help prevent run away queries. Setting the value to 0 disables the limit. # query-timeout = "0s"
# The time threshold when a query will be logged as a slow query. This limit can be set to help # discover slow or resource intensive queries. Setting the value to 0 disables the slow query logging. # log-queries-after = "0s"
# The maximum number of points a SELECT can process. A value of 0 will make # the maximum point count unlimited. This will only be checked every second so queries will not # be aborted immediately when hitting the limit. # max-select-point = 0
# The maximum number of series a SELECT can run. A value of 0 will make the maximum series # count unlimited. # max-select-series = 0
# The maxium number of group by time bucket a SELECT can create. A value of zero will max the maximum # number of buckets unlimited. # max-select-buckets = 0
### ### [retention] ### ### Controls the enforcement of retention policies for evicting old data. ###
# The interval of time when retention policy enforcement checks run. check-interval = "30m"
### ### [shard-precreation] ### ### Controls the precreation of shards, so they are available before data arrives. ### Only shards that, after creation, will have both a start- and end-time in the ### future, will ever be created. Shards are never precreated that would be wholly ### or partially in the past.
[shard-precreation] # Determines whether shard pre-creation service is enabled. enabled = true
# The interval of time when the check to pre-create new shards runs. check-interval = "10m"
# The default period ahead of the endtime of a shard group that its successor # group is created. advance-period = "30m"
### ### Controls the system self-monitoring, statistics and diagnostics. ### ### The internal database for monitoring data is created automatically if ### if it does not already exist. The target retention within this database ### is called 'monitor' and is also created with a retention period of 7 days ### and a replication factor of 1, if it does not exist. In all cases the ### this retention policy is configured as the default for the database.
[monitor] # Whether to record statistics internally. store-enabled = true
# The destination database for recorded statistics store-database = "_internal"
# The interval at which to record statistics store-interval = "10s"
### ### [http] ### ### Controls how the HTTP endpoints are configured. These are the primary ### mechanism for getting data into and out of InfluxDB. ###
# Determines whether the pprof endpoint is enabled. This endpoint is used for # troubleshooting and monitoring. # pprof-enabled = true
# Determines whether HTTPS is enabled. # https-enabled = false
# The SSL certificate to use when HTTPS is enabled. # https-certificate = "/etc/ssl/influxdb.pem"
# Use a separate private key location. # https-private-key = ""
# The JWT auth shared secret to validate requests using JSON web tokens. # shared-secret = ""
# The default chunk size for result sets that should be chunked. # max-row-limit = 0
# The maximum number of HTTP connections that may be open at once. New connections that # would exceed this limit are dropped. Setting this value to 0 disables the limit. # max-connection-limit = 0
# Enable http service over unix domain socket # unix-socket-enabled = false
# The path of the unix domain socket. # bind-socket = "/var/run/influxdb.sock"
# The maximum size of a client request body, in bytes. Setting this value to 0 disables the limit. # max-body-size = 25000000
# These next lines control how batching works. You should have this enabled # otherwise you could get dropped metrics or poor performance. Batching # will buffer points in memory if you have many coming in.
# Flush if this many points get buffered # batch-size = 5000
# number of batches that may be pending in memory # batch-pending = 10
# Flush at least this often even if we haven't hit buffer limit # batch-timeout = "1s"
# UDP Read buffer size, 0 means OS default. UDP listener will fail if set above OS max. # udp-read-buffer = 0
### This string joins multiple matching 'measurement' values providing more control over the final measurement name. # separator = "."
### Default tags that will be added to all metrics. These can be overridden at the template level ### or by tags extracted from metric # tags = ["region=us-east", "zone=1c"]
### Each template line requires a template pattern. It can have an optional ### filter before the template and separated by spaces. It can also have optional extra ### tags following the template. Multiple tags should be separated by commas and no spaces ### similar to the line protocol format. There can be only one default template. # templates = [ # "*.app env.service.resource.measurement", # # Default template # "server.*", # ]
### ### [collectd] ### ### Controls one or many listeners for collectd data. ###
[[collectd]] # enabled = false # bind-address = ":25826" # database = "collectd" # retention-policy = "" # # The collectd service supports either scanning a directory for multiple types # db files, or specifying a single db file. # typesdb = "/usr/local/share/collectd" # # security-level = "none" # auth-file = "/etc/collectd/auth_file"
# These next lines control how batching works. You should have this enabled # otherwise you could get dropped metrics or poor performance. Batching # will buffer points in memory if you have many coming in.
# Flush if this many points get buffered # batch-size = 5000
# Number of batches that may be pending in memory # batch-pending = 10
# Flush at least this often even if we haven't hit buffer limit # batch-timeout = "10s"
# UDP Read buffer size, 0 means OS default. UDP listener will fail if set above OS max. # read-buffer = 0
# Multi-value plugins can be handled two ways. # "split" will parse and store the multi-value plugin data into separate measurements # "join" will parse and store the multi-value plugin as a single multi-value measurement. # "split" is the default behavior for backward compatability with previous versions of influxdb. # parse-multivalue-plugin = "split" ### ### [opentsdb] ### ### Controls one or many listeners for OpenTSDB data. ###
# Log an error for every malformed point. # log-point-errors = true
# These next lines control how batching works. You should have this enabled # otherwise you could get dropped metrics or poor performance. Only points # metrics received over the telnet protocol undergo batching.
# Flush if this many points get buffered # batch-size = 1000
# Number of batches that may be pending in memory # batch-pending = 5
# Flush at least this often even if we haven't hit buffer limit # batch-timeout = "1s"
### ### [[udp]] ### ### Controls the listeners for InfluxDB line protocol data via UDP. ###
# These next lines control how batching works. You should have this enabled # otherwise you could get dropped metrics or poor performance. Batching # will buffer points in memory if you have many coming in.
# Flush if this many points get buffered # batch-size = 5000
# Number of batches that may be pending in memory # batch-pending = 10
# Will flush at least this often even if we haven't hit buffer limit # batch-timeout = "1s"
# UDP Read buffer size, 0 means OS default. UDP listener will fail if set above OS max. # read-buffer = 0
### ### [continuous_queries] ### ### Controls how continuous queries are run within InfluxDB. ###
[continuous_queries] # Determines whether the continuous query service is enabled. # enabled = true
# Controls whether queries are logged when executed by the CQ service. # log-enabled = true
# Controls whether queries are logged to the self-monitoring data store. # query-stats-enabled = false
# interval for how often continuous queries will be checked if they need to run # run-interval = "1s"
四、使配置生效并打开数据库连接,双击influxd.exe就好,然后双击influx.exe进行操作,网上有操作教程,注意操作数据库时不能关闭influxd.exe,我不知道为什么总有这么个提示:There was an error writing history file: open : The system cannot find the file specified.不过好像没啥影响
root@f216e9be15bf:/ Connected to http: InfluxDB shell version: 1.3.5 > create database cadvisor > show databases name: databases name ---- _internal cadvisor > CREATE USER testuser WITH PASSWORD 'testpwd' > GRANT ALL PRIVILEGES ON cadvisor TO testuser > CREATE RETENTION POLICY "cadvisor_retention" ON "cadvisor" DURATION 30d REPLICATION 1 DEFAULT
influxdb里面有一些重要概念:database,timestamp,field key, field value, field set,tag key,tag value,tag set,measurement, retention policy ,series,point。结合下面的例子数据来说明这几个概念:
> SELECT * FROM "h2o_feet" WHERE time >= '2015-08-17T23:48:00Z' AND time <= '2015-08-18T00:30:00Z' name: h2o_feet time level description location water_level ---- ----------------- -------- ----------- 2015-08-18T00:00:00Z between 6 and 9 feet coyote_creek 8.12 2015-08-18T00:00:00Z below 3 feet santa_monica 2.064 2015-08-18T00:06:00Z between 6 and 9 feet coyote_creek 8.005 2015-08-18T00:06:00Z below 3 feet santa_monica 2.116 2015-08-18T00:12:00Z between 6 and 9 feet coyote_creek 7.887 2015-08-18T00:12:00Z below 3 feet santa_monica 2.028 2015-08-18T00:18:00Z between 6 and 9 feet coyote_creek 7.762 2015-08-18T00:18:00Z below 3 feet santa_monica 2.126 2015-08-18T00:24:00Z between 6 and 9 feet coyote_creek 7.635 2015-08-18T00:24:00Z below 3 feet santa_monica 2.041 2015-08-18T00:30:00Z between 6 and 9 feet coyote_creek 7.5 2015-08-18T00:30:00Z below 3 feet santa_monica 2.051
GROUP BY,FILL()
如下语句中GROUP BY time(12m),* 表示以每12分钟和tag(location)分组(如果是GROUP BY time(12m)则表示仅每12分钟分组,GROUP BY 参数只能是time和tag)。然后fill(200)表示如果这个时间段没有数据,以200填充,mean(field_key)求该范围内数据的平均值(注意:这是依据series来计算。其他还有SUM求和,MEDIAN求中位数)。LIMIT 7表示限制返回的point(记录数)最多为7条,而SLIMIT 1则是限制返回的series为1个。
注意这里的时间区间,起始时间为整点前包含这个区间第一个12m的时间,比如这里为 2015-08-17T:23:48:00Z,第一条为 2015-08-17T23:48:00Z <= t < 2015-08-18T00:00:00Z这个区间的location=coyote_creek的water_level的平均值,这里没有数据,于是填充的200。第二条为 2015-08-18T00:00:00Z <= t < 2015-08-18T00:12:00Z区间的location=coyote_creek的water_level平均值,这里为 (8.12+8.005)/ 2 = 8.0625,其他以此类推。
而GROUP BY time(10m)则表示以10分钟分组,起始时间为包含这个区间的第一个10m的时间,即 2015-08-17T23:40:00Z。默认返回的是第一个series,如果要计算另外那个series,可以在SQL语句后面加上 SOFFSET 1。
那如果时间小于数据本身采集的时间间隔呢,比如GROUP BY time(10s)呢?这样的话,就会按10s取一个点,没有数值的为空或者FILL填充,对应时间点有数据则保持不变。
## GROUP BY time(12m) > SELECT mean("water_level") FROM "h2o_feet" WHERE time >= '2015-08-17T23:48:00Z' AND time <= '2015-08-18T00:30:00Z' GROUP BY time(12m),* fill(200) LIMIT 7 SLIMIT 1 name: h2o_feet tags: location=coyote_creek time mean ---- ---- 2015-08-17T23:48:00Z 200 2015-08-18T00:00:00Z 8.0625 2015-08-18T00:12:00Z 7.8245 2015-08-18T00:24:00Z 7.5675
## GROUP BY time(10m),SOFFSET设置为1 > SELECT mean("water_level") FROM "h2o_feet" WHERE time >= '2015-08-17T23:48:00Z' AND time <= '2015-08-18T00:30:00Z' GROUP BY time(10m),* fill(200) LIMIT 7 SLIMIT 1 SOFFSET 1 name: h2o_feet tags: location=santa_monica time mean ---- ---- 2015-08-17T23:40:00Z 200 2015-08-17T23:50:00Z 200 2015-08-18T00:00:00Z 2.09 2015-08-18T00:10:00Z 2.077 2015-08-18T00:20:00Z 2.041 2015-08-18T00:30:00Z 2.051
INTEGRAL(field_key, unit)
计算数值字段值覆盖的曲面的面积值并得到面积之和。测试数据如下:
1 2 3 4 5 6 7 8 9 10 11
> SELECT "water_level" FROM "h2o_feet" WHERE "location" = 'santa_monica' AND time >= '2015-08-18T00:00:00Z' AND time <= '2015-08-18T00:30:00Z'
# unit为默认的1秒 > SELECT INTEGRAL("water_level") FROM "h2o_feet" WHERE "location" = 'santa_monica' AND time >= '2015-08-18T00:00:00Z' AND time <= '2015-08-18T00:30:00Z' name: h2o_feet time integral ---- -------- 1970-01-01T00:00:00Z 3732.66
# unit为1分 > SELECT INTEGRAL("water_level", 1m) FROM "h2o_feet" WHERE "location" = 'santa_monica' AND time >= '2015-08-18T00:00:00Z' AND time <= '2015-08-18T00:30:00Z' name: h2o_feet time integral ---- -------- 1970-01-01T00:00:00Z 62.211
SPREAD(field_key)
计算数值字段的最大值和最小值的差值。
1 2 3 4 5 6 7 8
> SELECT SPREAD("water_level") FROM "h2o_feet" WHERE time >= '2015-08-17T23:48:00Z' AND time <= '2015-08-18T00:30:00Z' GROUP BY time(12m),* fill(18) LIMIT 3 SLIMIT 1 SOFFSET 1 name: h2o_feet tags: location=santa_monica time spread ---- ------ 2015-08-17T23:48:00Z 18 2015-08-18T00:00:00Z 0.052000000000000046 2015-08-18T00:12:00Z 0.09799999999999986
> SELECT STDDEV("water_level") FROM "h2o_feet" WHERE time >= '2015-08-17T23:48:00Z' AND time <= '2015-08-18T00:30:00Z' GROUP BY time(12m),* fill(18) SLIMIT 1; name: h2o_feet tags: location=coyote_creek time stddev ---- ------ 2015-08-17T23:48:00Z 18 2015-08-18T00:00:00Z 0.08131727983645186 2015-08-18T00:12:00Z 0.08838834764831845 2015-08-18T00:24:00Z 0.09545941546018377
> SELECT PERCENTILE("water_level",20) FROM "h2o_feet" WHERE time >= '2015-08-17T23:48:00Z' AND time <= '2015-08-18T00:30:00Z' GROUP BY time(12m) name: h2o_feet time percentile ---- ---------- 2015-08-17T23:48:00Z 2015-08-18T00:00:00Z 2.064 2015-08-18T00:12:00Z 2.028 2015-08-18T00:24:00Z 2.041
> SELECT PERCENTILE("water_level",40) FROM "h2o_feet" WHERE time >= '2015-08-17T23:48:00Z' AND time <= '2015-08-18T00:30:00Z' GROUP BY time(12m) name: h2o_feet time percentile ---- ---------- 2015-08-17T23:48:00Z 2015-08-18T00:00:00Z 2.116 2015-08-18T00:12:00Z 2.126 2015-08-18T00:24:00Z 2.051
SAMPLE(field_key, N)
随机返回field key的N个值。如果语句中有GROUP BY time(),则每组数据随机返回N个值。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
> SELECT SAMPLE("water_level",2) FROM "h2o_feet" WHERE time >= '2015-08-17T23:48:00Z' AND time <= '2015-08-18T00:30:00Z'; name: h2o_feet time sample ---- ------ 2015-08-18T00:00:00Z 2.064 2015-08-18T00:12:00Z 2.028
> SELECT SAMPLE("water_level",2) FROM "h2o_feet" WHERE time >= '2015-08-17T23:48:00Z' AND time <= '2015-08-18T00:30:00Z' GROUP BY time(12m); name: h2o_feet time sample ---- ------ 2015-08-18T00:06:00Z 2.116 2015-08-18T00:06:00Z 8.005 2015-08-18T00:12:00Z 7.887 2015-08-18T00:18:00Z 7.762 2015-08-18T00:24:00Z 7.635 2015-08-18T00:30:00Z 2.051
CUMULATIVE_SUM(field_key)
计算字段值的递增和。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
> SELECT CUMULATIVE_SUM("water_level") FROM "h2o_feet" WHERE time >= '2015-08-17T23:48:00Z' AND time <= '2015-08-18T00:30:00Z'; name: h2o_feet time cumulative_sum ---- -------------- 2015-08-18T00:00:00Z 8.12 2015-08-18T00:00:00Z 10.184 2015-08-18T00:06:00Z 18.189 2015-08-18T00:06:00Z 20.305 2015-08-18T00:12:00Z 28.192 2015-08-18T00:12:00Z 30.22 2015-08-18T00:18:00Z 37.982 2015-08-18T00:18:00Z 40.108 2015-08-18T00:24:00Z 47.742999999999995 2015-08-18T00:24:00Z 49.78399999999999 2015-08-18T00:30:00Z 57.28399999999999 2015-08-18T00:30:00Z 59.334999999999994
> SELECT DERIVATIVE("water_level") FROM "h2o_feet" WHERE "location" = 'santa_monica' AND time >= '2015-08-18T00:00:00Z' AND time <= '2015-08-18T00:30:00Z' name: h2o_feet time derivative ---- ---------- 2015-08-18T00:06:00Z 0.00014444444444444457 2015-08-18T00:12:00Z -0.00024444444444444465 2015-08-18T00:18:00Z 0.0002722222222222218 2015-08-18T00:24:00Z -0.000236111111111111 2015-08-18T00:30:00Z 0.00002777777777777842
> SELECT DERIVATIVE("water_level", 6m) FROM "h2o_feet" WHERE "location" = 'santa_monica' AND time >= '2015-08-18T00:00:00Z' AND time <= '2015-08-18T00:30:00Z' name: h2o_feet time derivative ---- ---------- 2015-08-18T00:06:00Z 0.052000000000000046 2015-08-18T00:12:00Z -0.08800000000000008 2015-08-18T00:18:00Z 0.09799999999999986 2015-08-18T00:24:00Z -0.08499999999999996 2015-08-18T00:30:00Z 0.010000000000000231
而DERIVATIVE结合GROUP BY time,以及mean可以构造更加复杂的查询,如下所示:
1 2 3 4 5 6 7 8 9 10 11 12 13 14
> SELECT DERIVATIVE(mean("water_level"), 6m) FROM "h2o_feet" WHERE time >= '2015-08-18T00:00:00Z' AND time <= '2015-08-18T00:30:00Z' group by time(12m), * name: h2o_feet tags: location=coyote_creek time derivative ---- ---------- 2015-08-18T00:12:00Z -0.11900000000000022 2015-08-18T00:24:00Z -0.12849999999999984
这个计算其实是先根据GROUP BY time求平均值,然后对这个平均值再做变化比的计算。因为数据是按12分钟分组的,而变化比的unit是6分钟,所以差值除以2(12/6)才得到变化比。如第一个值是 (7.8245-8.0625)/2 = -0.1190。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
> SELECT mean("water_level") FROM "h2o_feet" WHERE time >= '2015-08-18T00:00:00Z' AND time <= '2015-08-18T00:30:00Z' group by time(12m), * name: h2o_feet tags: location=coyote_creek time mean ---- ---- 2015-08-18T00:00:00Z 8.0625 2015-08-18T00:12:00Z 7.8245 2015-08-18T00:24:00Z 7.5675
name: h2o_feet tags: location=santa_monica time mean ---- ---- 2015-08-18T00:00:00Z 2.09 2015-08-18T00:12:00Z 2.077 2015-08-18T00:24:00Z 2.0460000000000003
> SELECT DERIVATIVE(mean("water_level"), 6m) FROM "h2o_feet" WHERE location='santa_monica' AND time >= '2015-08-18T00:00:00Z' AND time <= '2015-08-18T00:30:00Z' group by time(6m), * name: h2o_feet tags: location=santa_monica time derivative ---- ---------- 2015-08-18T00:06:00Z 0.052000000000000046 2015-08-18T00:12:00Z -0.08800000000000008 2015-08-18T00:18:00Z 0.09799999999999986 2015-08-18T00:24:00Z -0.08499999999999996 2015-08-18T00:30:00Z 0.010000000000000231
> SELECT NON_NEGATIVE_DERIVATIVE(mean("water_level"), 6m) FROM "h2o_feet" WHERE location='santa_monica' AND time >= '2015-08-18T00:00:00Z' AND time <= '2015-08-18T00:30:00Z' group by time(6m), * name: h2o_feet tags: location=santa_monica time non_negative_derivative ---- ----------------------- 2015-08-18T00:06:00Z 0.052000000000000046 2015-08-18T00:18:00Z 0.09799999999999986 2015-08-18T00:30:00Z 0.010000000000000231
CREATE CONTINUOUS QUERY <cq_name> ON <database_name> BEGIN <cq_query> END
cq_query格式: SELECT <function[s]> INTO <destination_measurement> FROM <measurement> [WHERE <stuff>] GROUP BY time(<interval>)[,<tag_key[s]>]
CQ操作的是实时数据,它使用本地服务器的时间戳、GROUP BY time()时间间隔以及InfluxDB预先设置好的时间范围来确定什么时候开始查询以及查询覆盖的时间范围。注意CQ语句里面的WHERE条件是没有时间范围的,因为CQ会根据GROUP BY time()自动确定时间范围。
CQ执行的时间间隔和GROUP BY time()的时间间隔一样,它在InfluxDB预先设置的时间范围的起始时刻执行。如果GROUP BY time(1h),则单次查询的时间范围为 now()-GROUP BY time(1h)到 now(),也就是说,如果当前时间为17点,这次查询的时间范围为 16:00到16:59.99999。
At 8:00 cq_basic 执行查询,查询时间范围 time >= '7:00' AND time < '08:00'. cq_basic写入一条记录到 average_passengers: name: average_passengers ------------------------ time mean 2016-08-28T07:00:00Z 7 At 9:00 cq_basic 执行查询,查询时间范围 time >= '8:00' AND time < '9:00'. cq_basic写入一条记录到 average_passengers: name: average_passengers ------------------------ time mean 2016-08-28T08:00:00Z 13.75
# Results > SELECT * FROM "average_passengers" name: average_passengers ------------------------ time mean 2016-08-28T07:00:00Z 7 2016-08-28T08:00:00Z 13.75
示例2 自动缩小取样并存储到新的保留策略(Retention Policy)中
1 2 3 4
CREATE CONTINUOUS QUERY "cq_basic_rp" ON "transportation" BEGIN SELECT mean("passengers") INTO "transportation"."three_weeks"."average_passengers" FROM "bus_data" GROUP BY time(1h) END
> SELECT * FROM "transportation"."three_weeks"."average_passengers" name: average_passengers ------------------------ time mean 2016-08-28T07:00:00Z 7 2016-08-28T08:00:00Z 13.75
示例3 使用后向引用(backreferencing)自动缩小取样并存储到新的数据库中
1 2 3 4
CREATE CONTINUOUS QUERY "cq_basic_br" ON "transportation" BEGIN SELECT mean(*) INTO "downsampled_transportation"."autogen".:MEASUREMENT FROM /.*/ GROUP BY time(30m),* END
CREATE CONTINUOUS QUERY "cq_basic_offset" ON "transportation" BEGIN SELECT mean("passengers") INTO "average_passengers" FROM "bus_data" GROUP BY time(1h,15m) END
与前面几个示例不同的是,这里的GROUP BY time(1h, 15m)指定了一个时间偏移,也就是说 cq_basic_offset执行的时间不再是整点,而是往后偏移15分钟。执行流程如下:
1 2 3 4 5 6 7 8 9 10
At 8:15 cq_basic_offset 执行查询的时间范围 time >= '7:15' AND time < '8:15'. name: average_passengers ------------------------ time mean 2016-08-28T07:15:00Z 7.75 At 9:15 cq_basic_offset 执行查询的时间范围 time >= '8:15' AND time < '9:15'. name: average_passengers ------------------------ time mean 2016-08-28T08:15:00Z 16.75
最终结果:
1 2 3 4 5 6
> SELECT * FROM "average_passengers" name: average_passengers ------------------------ time mean 2016-08-28T07:15:00Z 7.75 2016-08-28T08:15:00Z 16.75
4.2 高级语法
InfluxDB连续查询的高级语法如下:
1 2 3 4 5
CREATE CONTINUOUS QUERY <cq_name> ON <database_name> RESAMPLE EVERY <interval> FOR <interval> BEGIN <cq_query> END
CREATE CONTINUOUS QUERY "cq_advanced_every" ON "transportation" RESAMPLE EVERY 30m BEGIN SELECT mean("passengers") INTO "average_passengers" FROM "bus_data" GROUP BY time(1h) END
这里配置了30分钟执行一次CQ,没有指定FOR interval,于是查询的时间范围还是GROUP BY time(1h)指定的一个小时,执行流程如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
At 8:00, cq_advanced_every 执行时间范围 time >= '7:00' AND time < '8:00'. name: average_passengers ------------------------ time mean 2016-08-28T07:00:00Z 7 At 8:30, cq_advanced_every 执行时间范围 time >= '8:00' AND time < '9:00'. name: average_passengers ------------------------ time mean 2016-08-28T08:00:00Z 12.6667 At 9:00, cq_advanced_every 执行时间范围 time >= '8:00' AND time < '9:00'. name: average_passengers ------------------------ time mean 2016-08-28T08:00:00Z 13.75
> SELECT * FROM "average_passengers" name: average_passengers ------------------------ time mean 2016-08-28T07:00:00Z 7 2016-08-28T08:00:00Z 13.75
示例2 只配置查询时间范围
1 2 3 4 5
CREATE CONTINUOUS QUERY "cq_advanced_for" ON "transportation" RESAMPLE FOR 1h BEGIN SELECT mean("passengers") INTO "average_passengers" FROM "bus_data" GROUP BY time(30m) END
只配置了时间范围,而没有配置EVERY interval。这样,执行的时间间隔与GROUP BY time(30m)一样为30分钟,而查询的时间范围为1小时,由于是按30分钟分组,所以每次会写入两条记录。执行流程如下:
At 8:00 cq_advanced_for 查询时间范围:time >= '7:00' AND time < '8:00'. 写入两条记录。 name: average_passengers ------------------------ time mean 2016-08-28T07:00:00Z 6.5 2016-08-28T07:30:00Z 7.5 At 8:30 cq_advanced_for 查询时间范围:time >= '7:30' AND time < '8:30'. 写入两条记录。 name: average_passengers ------------------------ time mean 2016-08-28T07:30:00Z 7.5 2016-08-28T08:00:00Z 11.5 At 9:00 cq_advanced_for 查询时间范围:time >= '8:00' AND time < '9:00'. 写入两条记录。 name: average_passengers ------------------------ time mean 2016-08-28T08:00:00Z 11.5 2016-08-28T08:30:00Z 16
需要注意的是,cq_advanced_for每次写入了两条记录,重复的记录会被覆盖。
最终结果:
1 2 3 4 5 6 7 8
> SELECT * FROM "average_passengers" name: average_passengers ------------------------ time mean 2016-08-28T07:00:00Z 6.5 2016-08-28T07:30:00Z 7.5 2016-08-28T08:00:00Z 11.5 2016-08-28T08:30:00Z 16
示例3 同时配置执行时间间隔和查询时间范围
1 2 3 4 5
CREATE CONTINUOUS QUERY "cq_advanced_every_for" ON "transportation" RESAMPLE EVERY 1h FOR 90m BEGIN SELECT mean("passengers") INTO "average_passengers" FROM "bus_data" GROUP BY time(30m) END
At 8:00 cq_advanced_every_for 查询时间范围 time >= '6:30' AND time < '8:00'. 插入三条记录 name: average_passengers ------------------------ time mean 2016-08-28T06:30:00Z 3 2016-08-28T07:00:00Z 6.5 2016-08-28T07:30:00Z 7.5 At 9:00 cq_advanced_every_for 查询时间范围 time >= '7:30' AND time < '9:00'. 插入三条记录 name: average_passengers ------------------------ time mean 2016-08-28T07:30:00Z 7.5 2016-08-28T08:00:00Z 11.5 2016-08-28T08:30:00Z 16
最终结果:
1 2 3 4 5 6 7 8 9
> SELECT * FROM "average_passengers" name: average_passengers ------------------------ time mean 2016-08-28T06:30:00Z 3 2016-08-28T07:00:00Z 6.5 2016-08-28T07:30:00Z 7.5 2016-08-28T08:00:00Z 11.5 2016-08-28T08:30:00Z 16
示例4 配置查询时间范围和FILL填充
1 2 3 4 5
CREATE CONTINUOUS QUERY "cq_advanced_for_fill" ON "transportation" RESAMPLE FOR 2h BEGIN SELECT mean("passengers") INTO "average_passengers" FROM "bus_data" GROUP BY time(1h) fill(1000) END
在前面值配置查询时间范围的基础上,加上FILL填充空的记录。执行流程如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
At 6:00, cq_advanced_for_fill 查询时间范围:time >= '4:00' AND time < '6:00',没有数据,不填充。
At 7:00, cq_advanced_for_fill 查询时间范围:time >= '5:00' AND time < '7:00'. 写入两条记录,没有数据的时间点填充1000。 ------------------------ time mean 2016-08-28T05:00:00Z 1000 <------ fill(1000) 2016-08-28T06:00:00Z 3 <------ average of 2 and 4
[…] At 11:00, cq_advanced_for_fill 查询时间范围:time >= '9:00' AND time < '11:00'.写入两条记录,没有数据的点填充1000。 name: average_passengers ------------------------ 2016-08-28T09:00:00Z 20 <------ average of 20 2016-08-28T10:00:00Z 1000 <------ fill(1000)
At 12:00, cq_advanced_for_fill 查询时间范围:time >= '10:00' AND time < '12:00'。没有数据,不填充。
最终结果:
1 2 3 4 5 6 7 8 9 10
> SELECT * FROM "average_passengers" name: average_passengers ------------------------ time mean 2016-08-28T05:00:00Z 1000 2016-08-28T06:00:00Z 3 2016-08-28T07:00:00Z 7 2016-08-28T08:00:00Z 13.75 2016-08-28T09:00:00Z 20 2016-08-28T10:00:00Z 1000
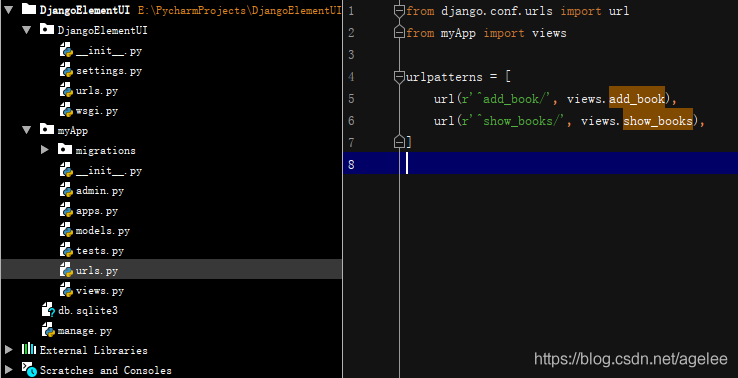
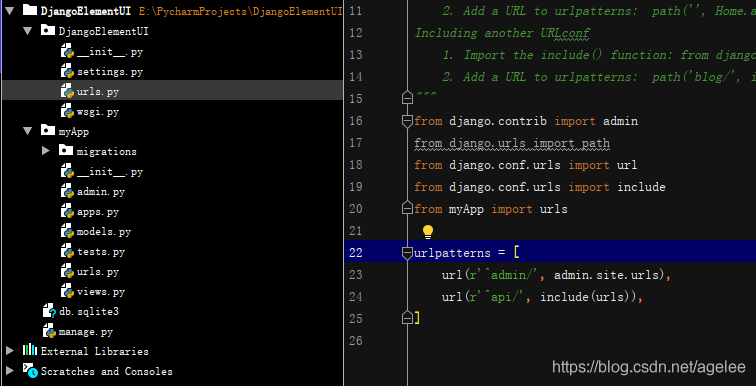
from __future__ import unicode_literals from django.shortcuts import render from django.http import HttpResponse import json from django.core import serializers from django.utils import timezone from crud.models import Books
import Router from 'vue-router'import HelloWorld from '@/components/HelloWorld'import Student from '@/components/Student'export default new Router({
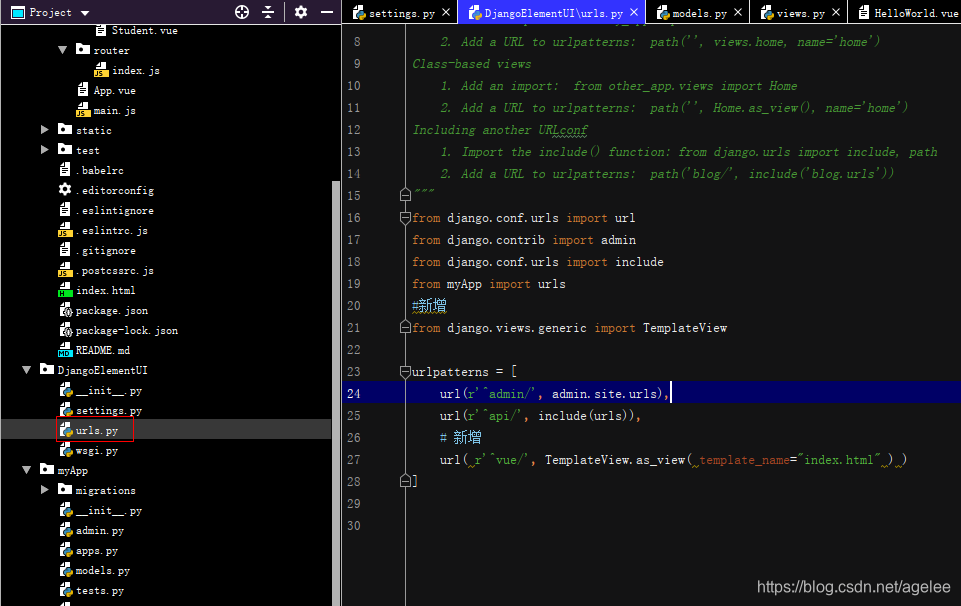
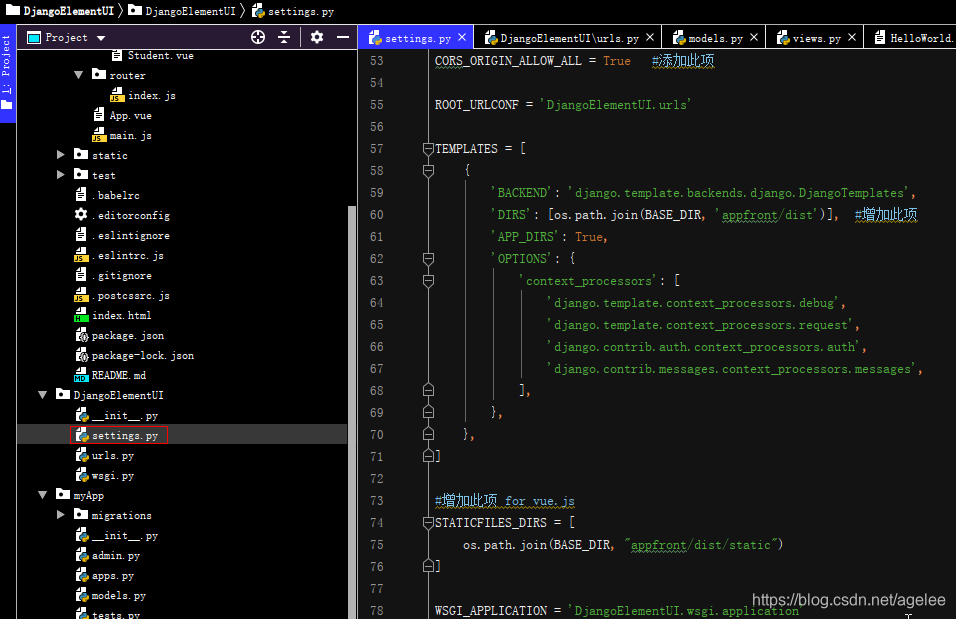
appfront文件夹下的main.js中引入ElementUI并注册.
1
import router from './router'import '../node_modules/element-ui/lib/theme-chalk/index.css'import ElementUI from 'element-ui'Vue.config.productionTip = false
import router from './router'import '../node_modules/element-ui/lib/theme-chalk/index.css'import ElementUI from 'element-ui'import VueResource from 'vue-resource'Vue.config.productionTip = false