wpa_supplicant及wpa_cli使用方法
wpa_supplicant是一个连接、配置WIFI的工具,它主要包含wpa_supplicant与wpa_cli两个程序。通常情况下,可以通过wpa_cli来进行WIFI的配置与连接,如果有特殊的需要,可以编写应用程序直接调用wpa_supplicant的接口直接开发。
启动wpa_supplicant应用
1 | wpa_supplicant -D nl80211 -i wlan0 -c /etc/wpa_supplicant.conf -B |
/etc/wpa_supplicant.conf文件里,添加下面代码:
1 | ctrl_interface=/var/run/wpa_supplicant update_config=1 |
启动wpa_cli应用
1 | $ wpa_cli -i wlan0 scan # 搜索附近wifi网络 |
如果要连接加密方式是[WPA-PSK-CCMP+TKIP][WPA2-PSK-CCMP+TKIP][ESS] (wpa加密),wifi名称是name,wifi密码是:psk。
1 | $ wpa_cli -i wlan0 set_network 0 ssid '"name"' |
如果要连接加密方式是[WEP][ESS] (wep加密),wifi名称是name,wifi密码是psk。
1 | $ wpa_cli -i wlan0 set_network 0 ssid '"name"' |
如果要连接加密方式是[ESS] (无加密),wifi名称是name。
1 | $ wpa_cli -i wlan0 set_network 0 ssid '"name"' |
分配ip/netmask/gateway/dns
1 | udhcpc -i wlan0 -s /etc/udhcpc.script -q |
执行完毕,就可以连接网络了。
保存连接
1 | $ wpa_cli -i wlan0 save_config |
断开连接
1 | $ wpa_cli -i wlan0 disable_network 0 |
连接已有的连接
1 | $ wpa_cli -i wlan0 list_network #列举所有保存的连接 |
断开wifi
1 | $ ifconfig wlan0 down |
wpa_wifi_tool使用方法
wpa_wifi_tool是基于wpa_supplicant及wpa_cli的一个用于快速设置wifi的工具,方便调试时连接wifi使用。使用方法:1、运行wpa_wifi_tool;2、输入help进行命令查看;3、s进行SSID扫描;4、c[n]进行wifi连接,连接时若为新的SSID则需输入密码,若为已保存的SSID则可以使用保存过的密码或者重新输入密码;5、e退出工具。
Windows InfluxDB 安装与配置
一、下载链接https://portal.influxdata.com/downloads,选windows版
二、解压到安装盘,目录如下
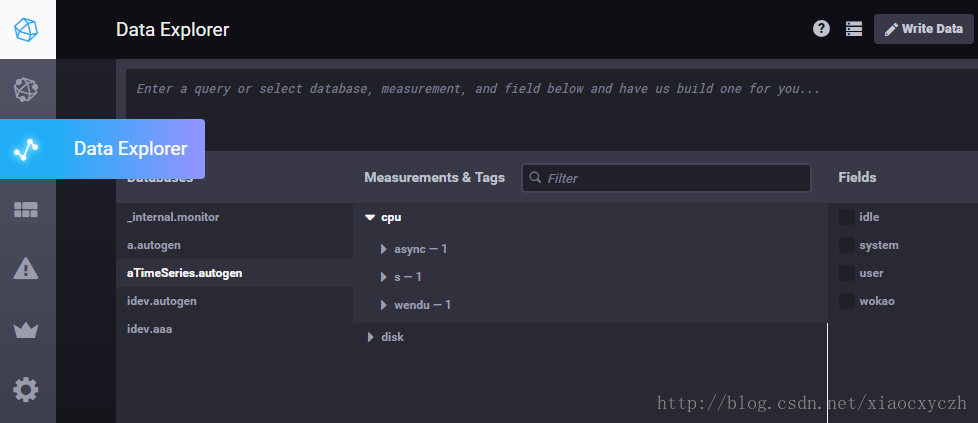
三、修改conf文件,代码如下,直接复制粘贴(1.4.2版本),注意修改路径,带D盘的改为你的安装路径就好,一共三个,注意网上有配置admin进行web管理,但新版本配置文件里没有admin因为官方给删除了,需下载Chronograf,后文会介绍
1 | ### Welcome to the InfluxDB configuration file. |
四、使配置生效并打开数据库连接,双击influxd.exe就好,然后双击influx.exe进行操作,网上有操作教程,注意操作数据库时不能关闭influxd.exe,我不知道为什么总有这么个提示:There was an error writing history file: open : The system cannot find the file specified.不过好像没啥影响
五、要使用web管理需要下载Chronograf,https://portal.influxdata.com/downloads第三个就是,下载完直接解压,双击exe程序,在浏览器输入http://localhost:8888/,一开始登录要账户密码,我都用admin就进去了
这个是查看建立的数据库
这个是查看数据库的数据
没了
git subtree教程
关于子仓库或者说是仓库共用,git官方推荐的工具是git subtree。 我自己也用了一段时间的git subtree,感觉比git submodule好用,但是也有一些缺点,在可接受的范围内。
所以对于仓库共用,在git subtree 与 git submodule之中选择的话,我推荐git subtree。
git subtree 可以实现一个仓库作为其他仓库的子仓库。
使用git subtree 有以下几个原因:
- 旧版本的git也支持(最老版本可以到 v1.5.2).
- git subtree与git submodule不同,它不增加任何像
.gitmodule这样的新的元数据文件. - git subtree对于项目中的其他成员透明,意味着可以不知道git subtree的存在.
当然,git subtree也有它的缺点,但是这些缺点还在可以接受的范围内:
- 必须学习新的指令(如:git subtree).
- 子仓库的更新与推送指令相对复杂。
git subtree的主要命令有:
1 | git subtree add --prefix=<prefix> <commit> |
准备
我们先准备一个仓库叫photoshop,一个仓库叫libpng,然后我们希望把libpng作为photoshop的子仓库。
photoshop的路径为https://github.com/test/photoshop.git,仓库里的文件有:
1 | photoshop |
libPNG的路径为https://github.com/test/libpng.git,仓库里的文件有:
1 | libpng |
以下操作均位于父仓库的根目录中。
在父仓库中新增子仓库
我们执行以下命令把libpng添加到photoshop中:
1 | git subtree add --prefix=sub/libpng https://github.com/test/libpng.git master --squash |
(--squash参数表示不拉取历史信息,而只生成一条commit信息。)
执行git status可以看到提示新增两条commit:
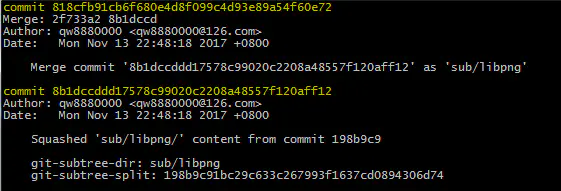
image
git log查看详细修改:
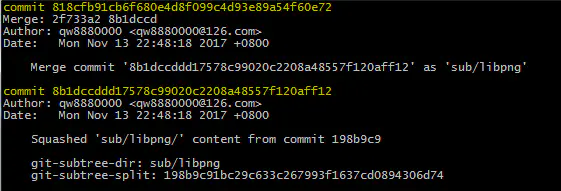
image
执行git push把修改推送到远端photoshop仓库,现在本地仓库与远端仓库的目录结构为:
1 | photoshop |
注意,现在的photoshop仓库对于其他项目人员来说,可以不需要知道libpng是一个子仓库。什么意思呢?
当你git clone或者git pull的时候,你拉取到的是整个photoshop(包括libpng在内,libpng就相当于photoshop里的一个普通目录);当你修改了libpng里的内容后执行git push,你将会把修改push到photoshop上。
也就是说photoshop仓库下的libpng与其他文件无异。
从源仓库拉取更新
如果源libpng仓库更新了,photoshop里的libpng如何拉取更新?使用git subtree pull,例如:
1 | git subtree pull --prefix=sub/libpng https://github.com/test/libpng.git master --squash |
推送修改到源仓库
如果在photoshop仓库里修改了libpng,然后想把这个修改推送到源libpng仓库呢?使用git subtree push,例如:
1 | git subtree push --prefix=sub/libpng https://github.com/test/libpng.git master |
简化git subtree命令
我们已经知道了git subtree 的命令的基本用法,但是上述几个命令还是显得有点复杂,特别是子仓库的源仓库地址,特别不方便记忆。
这里我们把子仓库的地址作为一个remote,方便记忆:
1 | git remote add -f libpng https://github.com/test/libpng.git |
然后可以这样来使用git subtree命令:
1 | git subtree add --prefix=sub/libpng libpng master --squash |
时序数据库InfluxDB使用详解
InfluxDB是一个开源的时序数据库,使用GO语言开发,特别适合用于处理和分析资源监控数据这种时序相关数据。而InfluxDB自带的各种特殊函数如求标准差,随机取样数据,统计数据变化比等,使数据统计和实时分析变得十分方便。在我们的容器资源监控系统中,就采用了InfluxDB存储cadvisor的监控数据。本文对InfluxDB的基本概念和一些特色功能做一个详细介绍,内容主要是翻译整理自官网文档,如有错漏,请指正。
这里说一下使用docker容器运行influxdb的步骤,物理机安装请参照官方文档。拉取镜像文件后运行即可,当前最新版本是1.3.5。启动容器时设置挂载的数据目录和开放端口。InfluxDB的操作语法InfluxQL与SQL基本一致,也提供了一个类似mysql-client的名为influx的CLI。InfluxDB本身是支持分布式部署多副本存储的,本文介绍都是针对的单节点单副本。
1 |
|
influxdb里面有一些重要概念:database,timestamp,field key, field value, field set,tag key,tag value,tag set,measurement, retention policy ,series,point。结合下面的例子数据来说明这几个概念:
1 | name: census |
timestamp
既然是时间序列数据库,influxdb的数据都有一列名为time的列,里面存储UTC时间戳。
field key,field value,field set
butterflies和honeybees两列数据称为字段(fields),influxdb的字段由field key和field value组成。其中butterflies和honeybees为field key,它们为string类型,用于存储元数据。
而butterflies这一列的数据12-7为butterflies的field value,同理,honeybees这一列的23-22为honeybees的field value。field value可以为string,float,integer或boolean类型。field value通常都是与时间关联的。
field key和field value对组成的集合称之为field set。如下:
1 | butterflies = 12 honeybees = 23 |
在influxdb中,字段必须存在。注意,字段是没有索引的。如果使用字段作为查询条件,会扫描符合查询条件的所有字段值,性能不及tag。类比一下,fields相当于SQL的没有索引的列。
tag key,tag value,tag set
location和scientist这两列称为标签(tags),标签由tag key和tag value组成。location这个tag key有两个tag value:1和2,scientist有两个tag value:langstroth和perpetua。tag key和tag value对组成了tag set,示例中的tag set如下:
1 | location = 1, scientist = langstroth |
tags是可选的,但是强烈建议你用上它,因为tag是有索引的,tags相当于SQL中的有索引的列。tag value只能是string类型 如果你的常用场景是根据butterflies和honeybees来查询,那么你可以将这两个列设置为tag,而其他两列设置为field,tag和field依据具体查询需求来定。
measurement
measurement是fields,tags以及time列的容器,measurement的名字用于描述存储在其中的字段数据,类似mysql的表名。如上面例子中的measurement为census。measurement相当于SQL中的表,本文中我在部分地方会用表来指代measurement。
retention policy
retention policy指数据保留策略,示例数据中的retention policy为默认的autogen。它表示数据一直保留永不过期,副本数量为1。你也可以指定数据的保留时间,如30天。
series
series是共享同一个retention policy,measurement以及tag set的数据集合。示例中数据有4个series,如下:
Arbitrary series number
Retention policy
Measurement
Tag set
series 1
autogen
census
location = 1,scientist = langstroth
series 2
autogen
census
location = 2,scientist = langstroth
series 3
autogen
census
location = 1,scientist = perpetua
series 4
autogen
census
location = 2,scientist = perpetua
point
point则是同一个series中具有相同时间的field set,points相当于SQL中的数据行。如下面就是一个point:
1 | name: census |
database
上面提到的结构都存储在数据库中,示例的数据库为my_database。一个数据库可以有多个measurement,retention policy, continuous queries以及user。influxdb是一个无模式的数据库,可以很容易的添加新的measurement,tags,fields等。而它的操作却和传统的数据库一样,可以使用类SQL语言查询和修改数据。
influxdb不是一个完整的CRUD数据库,它更像是一个CR-ud数据库。它优先考虑的是增加和读取数据而不是更新和删除数据的性能,而且它阻止了某些更新和删除行为使得创建和读取数据更加高效。
influxdb函数分为聚合函数,选择函数,转换函数,预测函数等。除了与普通数据库一样提供了基本操作函数外,还提供了一些特色函数以方便数据统计计算,下面会一一介绍其中一些常用的特色函数。
- 聚合函数:
FILL(),INTEGRAL(),SPREAD(),STDDEV(),MEAN(),MEDIAN()等。 - 选择函数:
SAMPLE(),PERCENTILE(),FIRST(),LAST(),TOP(),BOTTOM()等。 - 转换函数:
DERIVATIVE(),DIFFERENCE()等。 - 预测函数:
HOLT_WINTERS()。
先从官网导入测试数据(注:这里测试用的版本是1.3.1,最新版本是1.3.5):
1 | $ curl https://s3.amazonaws.com/noaa.water-database/NOAA_data.txt -o NOAA_data.txt |
下面的例子都以官方示例数据库来测试,这里只用部分数据以方便观察。measurement为h2o_feet,tag key为location,field key有level description和water_level两个。
1 | > SELECT * FROM "h2o_feet" WHERE time >= '2015-08-17T23:48:00Z' AND time <= '2015-08-18T00:30:00Z' |
GROUP BY,FILL()
如下语句中GROUP BY time(12m),* 表示以每12分钟和tag(location)分组(如果是GROUP BY time(12m)则表示仅每12分钟分组,GROUP BY 参数只能是time和tag)。然后fill(200)表示如果这个时间段没有数据,以200填充,mean(field_key)求该范围内数据的平均值(注意:这是依据series来计算。其他还有SUM求和,MEDIAN求中位数)。LIMIT 7表示限制返回的point(记录数)最多为7条,而SLIMIT 1则是限制返回的series为1个。
注意这里的时间区间,起始时间为整点前包含这个区间第一个12m的时间,比如这里为 2015-08-17T:23:48:00Z,第一条为 2015-08-17T23:48:00Z <= t < 2015-08-18T00:00:00Z这个区间的location=coyote_creek的water_level的平均值,这里没有数据,于是填充的200。第二条为 2015-08-18T00:00:00Z <= t < 2015-08-18T00:12:00Z区间的location=coyote_creek的water_level平均值,这里为 (8.12+8.005)/ 2 = 8.0625,其他以此类推。
而GROUP BY time(10m)则表示以10分钟分组,起始时间为包含这个区间的第一个10m的时间,即 2015-08-17T23:40:00Z。默认返回的是第一个series,如果要计算另外那个series,可以在SQL语句后面加上 SOFFSET 1。
那如果时间小于数据本身采集的时间间隔呢,比如GROUP BY time(10s)呢?这样的话,就会按10s取一个点,没有数值的为空或者FILL填充,对应时间点有数据则保持不变。
1 | ## GROUP BY time(12m) |
INTEGRAL(field_key, unit)
计算数值字段值覆盖的曲面的面积值并得到面积之和。测试数据如下:
1 | > SELECT "water_level" FROM "h2o_feet" WHERE "location" = 'santa_monica' AND time >= '2015-08-18T00:00:00Z' AND time <= '2015-08-18T00:30:00Z' |
使用INTERGRAL计算面积。注意,这个面积就是这些点连接起来后与时间围成的不规则图形的面积,注意unit默认是以1秒计算,所以下面语句计算结果为3732.66=2.028*1800+分割出来的梯形和三角形面积。如果unit改为1分,则结果为3732.66/60 = 62.211。unit为2分,则结果为3732.66/120 = 31.1055。以此类推。
1 | # unit为默认的1秒 |
SPREAD(field_key)
计算数值字段的最大值和最小值的差值。
1 | > SELECT SPREAD("water_level") FROM "h2o_feet" WHERE time >= '2015-08-17T23:48:00Z' AND time <= '2015-08-18T00:30:00Z' GROUP BY time(12m),* fill(18) LIMIT 3 SLIMIT 1 SOFFSET 1 |
STDDEV(field_key)
计算字段的标准差。influxdb用的是贝塞尔修正的标准差计算公式 ,如下:
- mean=(v1+v2+…+vn)/n;
- stddev = math.sqrt(
((v1-mean)2 + (v2-mean)2 + …+(vn-mean)2)/(n-1)
)
1 | > SELECT STDDEV("water_level") FROM "h2o_feet" WHERE time >= '2015-08-17T23:48:00Z' AND time <= '2015-08-18T00:30:00Z' GROUP BY time(12m),* fill(18) SLIMIT 1; |
PERCENTILE(field_key, N)
选取某个字段中大于N%的这个字段值。
如果一共有4条记录,N为10,则10%*4=0.4,四舍五入为0,则查询结果为空。N为20,则 20% * 4 = 0.8,四舍五入为1,选取的是4个数中最小的数。如果N为40,40% * 4 = 1.6,四舍五入为2,则选取的是4个数中第二小的数。由此可以看出N=100时,就跟MAX(field_key)是一样的,而当N=50时,与MEDIAN(field_key)在字段值为奇数个时是一样的。
1 | > SELECT PERCENTILE("water_level",20) FROM "h2o_feet" WHERE time >= '2015-08-17T23:48:00Z' AND time <= '2015-08-18T00:30:00Z' GROUP BY time(12m) |
SAMPLE(field_key, N)
随机返回field key的N个值。如果语句中有GROUP BY time(),则每组数据随机返回N个值。
1 | > SELECT SAMPLE("water_level",2) FROM "h2o_feet" WHERE time >= '2015-08-17T23:48:00Z' AND time <= '2015-08-18T00:30:00Z'; |
CUMULATIVE_SUM(field_key)
计算字段值的递增和。
1 | > SELECT CUMULATIVE_SUM("water_level") FROM "h2o_feet" WHERE time >= '2015-08-17T23:48:00Z' AND time <= '2015-08-18T00:30:00Z'; |
DERIVATIVE(field_key, unit) 和 NON_NEGATIVE_DERIVATIVE(field_key, unit)
计算字段值的变化比。unit默认为1s,即计算的是1秒内的变化比。
如下面的第一个数据计算方法是 (2.116-2.064)/(6*60) = 0.00014..,其他计算方式同理。虽然原始数据是6m收集一次,但是这里的变化比默认是按秒来计算的。如果要按6m计算,则设置unit为6m即可。
1 | > SELECT DERIVATIVE("water_level") FROM "h2o_feet" WHERE "location" = 'santa_monica' AND time >= '2015-08-18T00:00:00Z' AND time <= '2015-08-18T00:30:00Z' |
而DERIVATIVE结合GROUP BY time,以及mean可以构造更加复杂的查询,如下所示:
1 | > SELECT DERIVATIVE(mean("water_level"), 6m) FROM "h2o_feet" WHERE time >= '2015-08-18T00:00:00Z' AND time <= '2015-08-18T00:30:00Z' group by time(12m), * |
这个计算其实是先根据GROUP BY time求平均值,然后对这个平均值再做变化比的计算。因为数据是按12分钟分组的,而变化比的unit是6分钟,所以差值除以2(12/6)才得到变化比。如第一个值是 (7.8245-8.0625)/2 = -0.1190。
1 | > SELECT mean("water_level") FROM "h2o_feet" WHERE time >= '2015-08-18T00:00:00Z' AND time <= '2015-08-18T00:30:00Z' group by time(12m), * |
NON_NEGATIVE_DERIVATIVE与DERIVATIVE不同的是它只返回的是非负的变化比:
1 | > SELECT DERIVATIVE(mean("water_level"), 6m) FROM "h2o_feet" WHERE location='santa_monica' AND time >= '2015-08-18T00:00:00Z' AND time <= '2015-08-18T00:30:00Z' group by time(6m), * |
4.1 基本语法
连续查询(CONTINUOUS QUERY,简写为CQ)是指定时自动在实时数据上进行的InfluxQL查询,查询结果可以存储到指定的measurement中。基本语法格式如下:
1 | CREATE CONTINUOUS QUERY <cq_name> ON <database_name> |
CQ操作的是实时数据,它使用本地服务器的时间戳、GROUP BY time()时间间隔以及InfluxDB预先设置好的时间范围来确定什么时候开始查询以及查询覆盖的时间范围。注意CQ语句里面的WHERE条件是没有时间范围的,因为CQ会根据GROUP BY time()自动确定时间范围。
CQ执行的时间间隔和GROUP BY time()的时间间隔一样,它在InfluxDB预先设置的时间范围的起始时刻执行。如果GROUP BY time(1h),则单次查询的时间范围为 now()-GROUP BY time(1h)到 now(),也就是说,如果当前时间为17点,这次查询的时间范围为 16:00到16:59.99999。
下面看几个示例,示例数据如下,这是数据库transportation中名为bus_data的measurement,每15分钟统计一次乘客数和投诉数。数据文件bus_data.txt如下:
1 | # DDL |
导入数据,命令如下:
1 | root@f216e9be15bf:/# influx -import -path=bus_data.txt -precision=s |
示例1 自动缩小取样存储到新的measurement中
对单个字段自动缩小取样并存储到新的measurement中。
1 | CREATE CONTINUOUS QUERY "cq_basic" ON "transportation" |
这个CQ的意思就是对bus_data每小时自动计算取样数据的平均乘客数并存储到 average_passengers中。那么在2016-08-28这天早上会执行如下流程:
1 | At 8:00 cq_basic 执行查询,查询时间范围 time >= '7:00' AND time < '08:00'. |
示例2 自动缩小取样并存储到新的保留策略(Retention Policy)中
1 | CREATE CONTINUOUS QUERY "cq_basic_rp" ON "transportation" |
与示例1类似,不同的是保留的策略不是autogen,而是改成了three_weeks(创建保留策略语法 CREATE RETENTION POLICY "three_weeks" ON "transportation" DURATION 3w REPLICATION 1)。
1 | > SELECT * FROM "transportation"."three_weeks"."average_passengers" |
示例3 使用后向引用(backreferencing)自动缩小取样并存储到新的数据库中
1 | CREATE CONTINUOUS QUERY "cq_basic_br" ON "transportation" |
使用后向引用语法自动缩小取样并存储到新的数据库中。语法 :MEASUREMENT 用来指代后面的表,而 /.*/则是分别查询所有的表。这句CQ的含义就是每30分钟自动查询transportation的所有表(这里只有bus_data一个表),并将30分钟内数字字段(passengers和complaints)求平均值存储到新的数据库 downsampled_transportation中。
最终结果如下:
1 | > SELECT * FROM "downsampled_transportation."autogen"."bus_data" |
示例4 自动缩小取样以及配置CQ的时间范围
1 | CREATE CONTINUOUS QUERY "cq_basic_offset" ON "transportation" |
与前面几个示例不同的是,这里的GROUP BY time(1h, 15m)指定了一个时间偏移,也就是说 cq_basic_offset执行的时间不再是整点,而是往后偏移15分钟。执行流程如下:
1 | At 8:15 cq_basic_offset 执行查询的时间范围 time >= '7:15' AND time < '8:15'. |
最终结果:
1 | > SELECT * FROM "average_passengers" |
4.2 高级语法
InfluxDB连续查询的高级语法如下:
1 | CREATE CONTINUOUS QUERY <cq_name> ON <database_name> |
与基本语法不同的是,多了RESAMPLE关键字。高级语法里CQ的执行时间和查询时间范围则与RESAMPLE里面的两个interval有关系。
高级语法中CQ以EVERY interval的时间间隔执行,执行时查询的时间范围则是FOR interval来确定。如果FOR interval为2h,当前时间为17:00,则查询的时间范围为15:00-16:59.999999。RESAMPLE的EVERY和FOR两个关键字可以只有一个。
示例的数据表如下,比之前的多了几条记录为了示例3和示例4的测试:
1 | name: bus_data |
示例1 只配置执行时间间隔
1 | CREATE CONTINUOUS QUERY "cq_advanced_every" ON "transportation" |
这里配置了30分钟执行一次CQ,没有指定FOR interval,于是查询的时间范围还是GROUP BY time(1h)指定的一个小时,执行流程如下:
1 | At 8:00, cq_advanced_every 执行时间范围 time >= '7:00' AND time < '8:00'. |
需要注意的是,这里的 8点到9点这个区间执行了两次,第一次执行时时8:30,平均值是 (8+15+15)/ 3 = 12.6667,而第二次执行时间是9:00,平均值是 (8+15+15+17) / 4=13.75,而且最后第二个结果覆盖了第一个结果。InfluxDB如何处理重复的记录可以参见这个文档。
最终结果:
1 | > SELECT * FROM "average_passengers" |
示例2 只配置查询时间范围
1 | CREATE CONTINUOUS QUERY "cq_advanced_for" ON "transportation" |
只配置了时间范围,而没有配置EVERY interval。这样,执行的时间间隔与GROUP BY time(30m)一样为30分钟,而查询的时间范围为1小时,由于是按30分钟分组,所以每次会写入两条记录。执行流程如下:
1 | At 8:00 cq_advanced_for 查询时间范围:time >= '7:00' AND time < '8:00'. |
需要注意的是,cq_advanced_for每次写入了两条记录,重复的记录会被覆盖。
最终结果:
1 | > SELECT * FROM "average_passengers" |
示例3 同时配置执行时间间隔和查询时间范围
1 | CREATE CONTINUOUS QUERY "cq_advanced_every_for" ON "transportation" |
这里配置了执行间隔为1小时,而查询范围90分钟,最后分组是30分钟,每次插入了三条记录。执行流程如下:
1 | At 8:00 cq_advanced_every_for 查询时间范围 time >= '6:30' AND time < '8:00'. |
最终结果:
1 | > SELECT * FROM "average_passengers" |
示例4 配置查询时间范围和FILL填充
1 | CREATE CONTINUOUS QUERY "cq_advanced_for_fill" ON "transportation" |
在前面值配置查询时间范围的基础上,加上FILL填充空的记录。执行流程如下:
1 | At 6:00, cq_advanced_for_fill 查询时间范围:time >= '4:00' AND time < '6:00',没有数据,不填充。 |
最终结果:
1 | > SELECT * FROM "average_passengers" |