最全的Windows Azure学习教程汇总
Windows Azure 是微软基于云计算的操作系统,能够为开发者提供一个平台,帮助开发可运行在云服务器、数据中心、Web 和 PC 上的应用程序。
Azure 是一种灵活和支持互操作的平台,能够将处于云端的开发者个人能力,同微软全球数据中心网络托管的服务,比如存储、计算和网络基础设施服务,紧密结合起来。帮助开发者在“云端”和“客户端”同时部署应用,使得企业与用户都能共享资源。
本文整理了丰富的 Windows Azure 学习资源,帮助开发者能全面地学习 Windows Azure 知识,并将 Windows Azure 运用在项目和实际工作中。
通过本系列博客,先来了解一下 Windows Azure 平台的基本知识。Windows Azure,正如同桌面操作系统 Windows 和服务器操作系统 Windows Server 一样,是一个云端的操作系统。开发人员可以使用同一套技术:.NET(包括 Silverlight),或者 Win32,同时针对桌面,服务器,以及云,开发程序,而不需要针对某个平台学习专门的技术。Visual Studio 和 Expression Studio 为开发人员提供了强大的工具支持。
Windows Azure平台简介(二):Windows Azure
Windows Azure平台简介(三):AppFabric
Windows Azure平台简介(四):SQL Azure以及其他服务
在开始本教学之前,请确保你从 Windows Azure 平台下载下载并安装了最新的 Windows Azure 开发工具。本教学使用 Visual Studio 2010 作为开发工具。
Windows Azure入门教学系列 (一):创建第一个WebRole程序
Windows Azure入门教学系列 (二):部署第一个Web Role程序
Windows Azure入门教学系列 (三):创建第一个Worker Role程序
Windows Azure入门教学系列 (四):使用Blob Storage
Windows Azure入门教学系列 (五):使用Queue Storage
Windows Azure入门教学系列 (六):使用Table Storage
Windows Azure入门教学系列 (七):使用REST API访问Storage Service
Windows Azure入门教学系列 (八):使用Windows Azure Drive
Azure Storage 是微软 Azure 云提供的云端存储解决方案,当前支持的存储类型有 Blob、Queue、File 和 Table。

Azure Blob Storage 基本用法 – Azure Storage 之 Blob
Azure Queue Storage 基本用法 – Azure Storage 之 Queue
Azure File Storage 基本用法 – Azure Storage 之 File
Azure Table storage 基本用法 – Azure Storage 之 Table
Windows Azure Storage 支持三重冗余的。保存在 Azure Storage 的内容,会在同一个数据中心保留有3个副本。这样的好处显而易见:当数据中心发生一般性故障的时候,比如磁盘损坏,机架服务器损坏等,用户保存在 Azure Storage 的数据不会丢失。每次对于 Storage 的写操作,都会对三个副本进行同步写操作,等到在副本操作完毕之后,才会返回执行成功给客户端。
Windows Azure 提供了三种不同类型的存储服务(这里的存储是非关系型数据,比如图片、文档等文件),用来提供给 Windows Azure 上运行的应用程序存储数据使用。依据不同的存储格式会有不同的限制,因为这些存储服务都是以分散式巨量存储(Distributed Mass Storage)为核心概念所设计出来的,为了要达成快速在分散式存储空间中存储与管理数据(还包含高可用度的赘余存储管理),微软有在数据的存储上做一些限制。
微软还提供了 REST API 来方便用户操作 Storage Service。
(1)Windows Azure Storage Service存储服务
(2)Windows Azure Storage Service存储服务之Blob详解(上)
(3)Windows Azure Storage Service存储服务之Blob详解(中)
(4)Windows Azure Storage Service存储服务之Blob Share Access Signature
(6)Windows Azure Storage之Table
(7)使用工具管理Windows Azure Storage
(8)Windows Azure 上的托管服务CDN (上)
(9)Windows Azure 上的托管服务CDN (中) Blob Service
(10)Windows Azure 上的托管服务CDN (下) Hosted Service、
(11)计算你存储的Blob的大小
(14)使用Azure Blob的PutBlock方法,实现文件的分块、离线上传
(15)使用WCF服务,将本地图片上传至Azure Storage (上) 服务器端代码
(16)使用WCF服务,将本地图片上传至Azure Storage (上) 客户端代码
(17)Azure Storage读取访问地域冗余(Read Access – Geo Redundant Storage, RA-GRS)
(18)使用HTML5 Portal的Azure CDN服务
(19)再谈Azure Block Blob和Page Blob
(21)使用AzCopy工具,加快Azure Storage传输速度
PowerShell 是管理 Azure 的最好方式之一,通过使用 PowerShell 脚本可以把很多的工作自动化。比如对于 Azure 上的虚拟机,可以设置定时关机操作,并在适当的时间把它开机,这样就能减少虚拟机的运行时间,同时也能为节能减排做出贡献。
(1)PowerShell入门
(2)修改Azure订阅名称
(3)上传证书
(5)使用Azure PowerShell创建简单的Azure虚拟机和Linux虚拟机
(6)设置单个Virtual Machine Endpoint
(7)使用CSV文件批量设置Virtual Machine Endpoint
(9)使用PowerShell导出订阅下所有的Azure VM的Public IP和Private IP
(10)使用PowerShell导出订阅下所有的Azure VM和Cloud Service的高可用情况
(11)使用自定义虚拟机镜像模板,创建Azure虚拟机并绑定公网IP(VIP)和内网IP(DIP)
(12)通过Azure PowerShell创建SSH登录的Linux VM
SQL Azure 是微软基于 Microsoft SQL Server Denali,也就是 SQL Server 2012 构建的云端关系型数据库服务。SQL Azure 是 SQL Server 的一个大子集,能够实现 SQL Server 的绝大部分功能,并且将它们作为云端的服务来扩展。SQL Azure Database 提供内置的高精准、可用性、功效与其他功能。
(1)入门
(5)使用SQL Server Management Studio连接SQL Azure
(6)使用Project Houston管理SQL Azure
(7)在SQL Azure Database中执行的T-SQL
(8)使用Visual Studio 2010开发应用连接SQL Azure云端数据库
(9)把本地的SQL Server数据库迁移到SQL Azure云数据库上
(10)SQL Azure Data Sync数据同步功能(上)
(11)SQL Azure Data Sync数据同步功能(下)
(12)使用新Portal 创建 SQL Azure Database
(13)Azure的两种关系型数据库服务:SQL Azure与SQL Server VM的不同
(14)将云端SQL Azure中的数据库备份到本地SQL Server
(15)SQL Azure 新的规格
(17)SQL Azure V12 - 跨数据中心标准地域复制(Standard Geo-Replication)
(20)使用SQL Server 2016 Upgrade Advisor
(21)将整张表都迁移到Azure Stretch Database里
(22)迁移部分数据到Azure Stretch Database
1. 《Windows Azure 实战》全面深入,完整覆盖 Windows Azure 所有关键技术和理论,详细讲解云计算开发流程、云服务架构(可用性、可靠性和高性能)、云设备整合、系统整合,以及云计算项目的管理。
注重实战,68个精心策划的针对特定实际应用场景的真实案例,详细呈现案例的设计思路和完整实现步骤。

2. 《Windows Azure 从入门到精通》介绍了如何构建和管理云端的可扩展应用,一次一个知识点,同时辅之以适当的练习,可帮助读者轻松掌握基本的编程技能,掌握 Windows Azure 云计算平台的核心服务和特性,是一本理想的入门教程。

3. 《云计算与Azure平台实战》解决了从本地转移到基于云的应用程序时,可能面临的各种问题;展示了如何将 ASP.NET 身份验证和角色管理用应用于 Azure Web 角色;揭示了迁移到 Windows Azure 时把计算服务卸载到一个或多个 WorkerWeb 角色的益处;讲解如何为共享 Azure 表选择最合适的 PartionKey 和 RowKey 值的组合;探讨了改善 Azure 表的可扩展性和性能的方法。

4. 《走进云计算:Windows Azure实战手记》介绍了你必须学会的微软云开发技术,介绍目前最火爆的云计算,深入剖析微软最新的云开发平台,涵盖 Windows Azure 环境、存储服务、SQL Azure 数据库与 App Fabric 服务平台 Step by Step 递进教学,初学者可按部就班地学习云应用的开发技术。

相关阅读:
Azure Blob Storage 基本用法 – Azure Storage 之 Blob
Azure Queue Storage 基本用法 – Azure Storage 之 Queue
分布式ID生成方法生成演变
一、需求缘起
几乎所有的业务系统,都有生成一个记录标识的需求,例如:
(1)消息标识:message-id
(2)订单标识:order-id
(3)帖子标识:tiezi-id
这个记录标识往往就是数据库中的唯一主键,数据库上会建立聚集索引(cluster index),即在物理存储上以这个字段排序。
这个记录标识上的查询,往往又有分页或者排序的业务需求,例如:
(1)拉取最新的一页消息:selectmessage-id/ order by time/ limit 100
(2)拉取最新的一页订单:selectorder-id/ order by time/ limit 100
(3)拉取最新的一页帖子:selecttiezi-id/ order by time/ limit 100
所以往往要有一个time字段,并且在time字段上建立普通索引(non-cluster index)。
我们都知道普通索引存储的是实际记录的指针,其访问效率会比聚集索引慢,如果记录标识在生成时能够基本按照时间有序,则可以省去这个time字段的索引查询:
select message-id/ (order by message-id)/limit 100
再次强调,能这么做的前提是,message-id的生成基本是趋势时间递增的。
这就引出了记录标识生成(也就是上文提到的三个XXX-id)的两大核心需求:
(1)全局唯一
(2)趋势有序
这也是本文要讨论的核心问题:如何高效生成趋势有序的全局唯一ID。
二、常见方法、不足与优化
【常见方法一:使用数据库的 auto_increment 来生成全局唯一递增ID】
优点:
(1)简单,使用数据库已有的功能
(2)能够保证唯一性
(3)能够保证递增性
(4)步长固定
缺点:
(1)可用性难以保证:数据库常见架构是一主多从+读写分离,生成自增ID是写请求,主库挂了就玩不转了
(2)扩展性差,性能有上限:因为写入是单点,数据库主库的写性能决定ID的生成性能上限,并且难以扩展
改进方法:
(1)增加主库,避免写入单点
(2)数据水平切分,保证各主库生成的ID不重复
如上图所述,由1个写库变成3个写库,每个写库设置不同的auto_increment初始值,以及相同的增长步长,以保证每个数据库生成的ID是不同的(上图中库0生成0,3,6,9…,库1生成1,4,7,10,库2生成2,5,8,11…)
改进后的架构保证了可用性,但缺点是:
(1)丧失了ID生成的“绝对递增性”:先访问库0生成0,3,再访问库1生成1,可能导致在非常短的时间内,ID生成不是绝对递增的(这个问题不大,我们的目标是趋势递增,不是绝对递增)
(2)数据库的写压力依然很大,每次生成ID都要访问数据库
为了解决上述两个问题,引出了第二个常见的方案
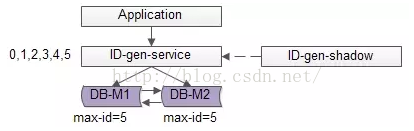
【常见方法二:单点批量ID生成服务】
分布式系统之所以难,很重要的原因之一是“没有一个全局时钟,难以保证绝对的时序”,要想保证绝对的时序,还是只能使用单点服务,用本地时钟保证“绝对时序”。数据库写压力大,是因为每次生成ID都访问了数据库,可以使用批量的方式降低数据库写压力。
如上图所述,数据库使用双master保证可用性,数据库中只存储当前ID的最大值,例如0。ID生成服务假设每次批量拉取6个ID,服务访问数据库,将当前ID的最大值修改为5,这样应用访问ID生成服务索要ID,ID生成服务不需要每次访问数据库,就能依次派发0,1,2,3,4,5这些ID了,当ID发完后,再将ID的最大值修改为11,就能再次派发6,7,8,9,10,11这些ID了,于是数据库的压力就降低到原来的1/6了。
优点:
(1)保证了ID生成的绝对递增有序
(2)大大的降低了数据库的压力,ID生成可以做到每秒生成几万几十万个
缺点:
(1)服务仍然是单点
(2)如果服务挂了,服务重启起来之后,继续生成ID可能会不连续,中间出现空洞(服务内存是保存着0,1,2,3,4,5,数据库中max-id是5,分配到3时,服务重启了,下次会从6开始分配,4和5就成了空洞,不过这个问题也不大)
(3)虽然每秒可以生成几万几十万个ID,但毕竟还是有性能上限,无法进行水平扩展
改进方法:
单点服务的常用高可用优化方案是“备用服务”,也叫“影子服务”,所以我们能用以下方法优化上述缺点(1):
如上图,对外提供的服务是主服务,有一个影子服务时刻处于备用状态,当主服务挂了的时候影子服务顶上。这个切换的过程对调用方是透明的,可以自动完成,常用的技术是vip+keepalived,具体就不在这里展开。
【常见方法三:uuid】
上述方案来生成ID,虽然性能大增,但由于是单点系统,总还是存在性能上限的。同时,上述两种方案,不管是数据库还是服务来生成ID,业务方Application都需要进行一次远程调用,比较耗时。有没有一种本地生成ID的方法,即高性能,又时延低呢?
uuid是一种常见的方案:string ID =GenUUID();
优点:
(1)本地生成ID,不需要进行远程调用,时延低
(2)扩展性好,基本可以认为没有性能上限
缺点:
(1)无法保证趋势递增
(2)uuid过长,往往用字符串表示,作为主键建立索引查询效率低,常见优化方案为“转化为两个uint64整数存储”或者“折半存储”(折半后不能保证唯一性)
【常见方法四:取当前毫秒数】
uuid是一个本地算法,生成性能高,但无法保证趋势递增,且作为字符串ID检索效率低,有没有一种能保证递增的本地算法呢?
取当前毫秒数是一种常见方案:uint64 ID = GenTimeMS();
优点:
(1)本地生成ID,不需要进行远程调用,时延低
(2)生成的ID趋势递增
(3)生成的ID是整数,建立索引后查询效率高
缺点:
(1)如果并发量超过1000,会生成重复的ID
我去,这个缺点要了命了,不能保证ID的唯一性。当然,使用微秒可以降低冲突概率,但每秒最多只能生成1000000个ID,再多的话就一定会冲突了,所以使用微秒并不从根本上解决问题。
【常见方法五:类snowflake算法】
snowflake是twitter开源的分布式ID生成算法,其核心思想是:一个long型的ID,使用其中41bit作为毫秒数,10bit作为机器编号,12bit作为毫秒内序列号。这个算法单机每秒内理论上最多可以生成1000*(2^12),也就是400W的ID,完全能满足业务的需求。
借鉴snowflake的思想,结合各公司的业务逻辑和并发量,可以实现自己的分布式ID生成算法。
举例,假设某公司ID生成器服务的需求如下:
(1)单机高峰并发量小于1W,预计未来5年单机高峰并发量小于10W
(2)有2个机房,预计未来5年机房数量小于4个
(3)每个机房机器数小于100台
(4)目前有5个业务线有ID生成需求,预计未来业务线数量小于10个
(5)…
分析过程如下:
(1)高位取从2016年1月1日到现在的毫秒数(假设系统ID生成器服务在这个时间之后上线),假设系统至少运行10年,那至少需要10年*365天*24小时*3600秒*1000毫秒=320*10^9,差不多预留39bit给毫秒数
(2)每秒的单机高峰并发量小于10W,即平均每毫秒的单机高峰并发量小于100,差不多预留7bit给每毫秒内序列号
(3)5年内机房数小于4个,预留2bit给机房标识
(4)每个机房小于100台机器,预留7bit给每个机房内的服务器标识
(5)业务线小于10个,预留4bit给业务线标识

这样设计的64bit标识,可以保证:
(1)每个业务线、每个机房、每个机器生成的ID都是不同的
(2)同一个机器,每个毫秒内生成的ID都是不同的
(3)同一个机器,同一个毫秒内,以序列号区区分保证生成的ID是不同的
(4)将毫秒数放在最高位,保证生成的ID是趋势递增的
缺点:
(1)由于“没有一个全局时钟”,每台服务器分配的ID是绝对递增的,但从全局看,生成的ID只是趋势递增的(有些服务器的时间早,有些服务器的时间晚)
最后一个容易忽略的问题:
生成的ID,例如message-id/ order-id/ tiezi-id,在数据量大时往往需要分库分表,这些ID经常作为取模分库分表的依据,为了分库分表后数据均匀,ID生成往往有“取模随机性”的需求,所以我们通常把每秒内的序列号放在ID的最末位,保证生成的ID是随机的。
又如果,我们在跨毫秒时,序列号总是归0,会使得序列号为0的ID比较多,导致生成的ID取模后不均匀。解决方法是,序列号不是每次都归0,而是归一个0到9的随机数,这个地方。
下面附上C#.Net 实现snowflake算法实现
1 | using System; |